Chapter 24 Augmented Data Structure
24.1 146. LRU Cache
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and put.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1. put(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
Follow up: Could you do both operations in O(1) time complexity?
Example:
LRUCache cache = new LRUCache( 2 /* capacity */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // returns 1
cache.put(3, 3); // evicts key 2
cache.get(2); // returns -1 (not found)
cache.put(4, 4); // evicts key 1
cache.get(1); // returns -1 (not found)
cache.get(3); // returns 3
cache.get(4); // returns 4https://leetcode.com/problems/lru-cache
Q: Why need to be
list<Key,Value>instead oflist<Value>, since there iskeyin map?
A: We cannot doerasein map without knowing key when capacity is beyond the limit.
struct LRUCache {
LRUCache(int capacity) : capa_(capacity) {}
int get(int key) {
if (map_.count(key)) { // It key exists, update it.
const auto value = map_[key]->second;
update(key, value);
return value;
}
return -1;
}
void put(int key, int value) {
// If cache is full while inserting, remove the last one.
if (map_.count(key) == 0 && list_.size() == capa_) {
auto del = list_.back(); list_.pop_back();
map_.erase(del.first);
}
update(key, value);
}
private:
list<pair<int, int>> list_; // key, value
unordered_map<int, list<pair<int, int>>::iterator> map_; // key, list iterator
int capa_;
// Update (key, iterator of (key, value)) pair
void update(int key, int value) {
if(map_.count(key)) list_.erase(map_[key]);
list_.emplace_front(key, value);
map_[key] = list_.begin();
}
};- list 是按照时间顺序连接节点的
- get和put都可能要update底层的数据结构(map+list).
A better solution with list’s splice function:
class LRUCache {
int cap=0;
using KEY=int;
using VALUE=int;
list<pair<KEY,VALUE>> ls;
map<KEY, list<pair<KEY,VALUE>>::iterator> m;
/////dont have to destruct and constr...the node
void promote(list<pair<KEY,VALUE>>::iterator it){
if(it!=ls.begin())
// move the iterator to front
ls.splice(ls.begin(), ls, /**/it, next(it)/**/);
}
public:
LRUCache(int capacity) { cap=capacity; }
int get(int key) {
if(m.count(key)){
VALUE v=m[key]->second;
promote(m.at(key));
return v;
}
return -1;
}
void put(int key, int value) {
if(m.count(key)){
promote(m[key]);
if(m[key]->second!=value) // the value could be updated
m[key]->second=value;
}else{ // new item
ls.emplace_front(key, value);
m[key] = ls.begin();
if(ls.size()>cap){
////This is why we need to use list<pair> instead of list<VALUE>
m.erase(ls.back().first);
ls.pop_back();
}
}
}
};- Java
This is the laziest implementation using Java’s LinkedHashMap. In the real interview, however, it is definitely not what interviewer expected.
import java.util.LinkedHashMap;
public class LRUCache {
private LinkedHashMap<Integer, Integer> map;
private final int CAPACITY;
public LRUCache(int capacity) {
CAPACITY = capacity;
map = new LinkedHashMap<Integer, Integer>(capacity, 0.75f, true){
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > CAPACITY;
}
};
}
public int get(int key) {
return map.getOrDefault(key, -1);
}
public void set(int key, int value) {
map.put(key, value);
}
}https://stackoverflow.com/questions/20772869/what-is-the-use-of-linkedhashmap-removeeldestentry
Or
public class LRUCache {
LinkedHashMap<Integer,Integer> cache=new LinkedHashMap<>();
int cap=0;
public LRUCache(int capacity) {
cap=capacity;
}
public int get(int key) {
if(cache.containsKey(key)) {
int value=cache.get(key);
cache.remove(key);
cache.put(key,value);
return value;
}
return -1;
}
public void put(int key, int value) {
if(cache.containsKey(key)) {
cache.remove(key);
cache.put(key,value);
}
else if(cache.size() == cap) cache.remove(cache.entrySet().iterator().next().getKey());
cache.put(key,value);
}
}24.2 460. LFU Cache
Design and implement a data structure for Least Frequently Used (LFU) cache. It should support the following operations: get and put.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1. put(key, value) - Set or insert the value if the key is not already present. When the cache reaches its capacity, it should invalidate the least frequently used item before inserting a new item. For the purpose of this problem, when there is a tie (i.e., two or more keys that have the same frequency), the least recently used key would be evicted.
Follow up: Could you do both operations in \(O(1)\) time complexity?
Example:
LFUCache cache = new LFUCache( 2 /* capacity */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // returns 1
cache.put(3, 3); // evicts key 2
cache.get(2); // returns -1 (not found)
cache.get(3); // returns 3.
cache.put(4, 4); // evicts key 1.
cache.get(1); // returns -1 (not found)
cache.get(3); // returns 3
cache.get(4); // returns 4https://leetcode.com/problems/lfu-cache
Design and implement a data structure for Least Frequently Used (LFU) cache. It should support the following operations: get and put.
- get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.
- put(key, value) - Set or insert the value if the key is not already present. When the cache reaches its capacity, it should invalidate the least frequently used item before inserting a new item. For the purpose of this problem, when there is a tie (i.e., two or more keys that have the same frequency), the least recently used key would be evicted.
Follow up: Could you do both operations in O(1) time complexity?
Example:
LFUCache cache = new LFUCache( 2 /* capacity */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // returns 1
cache.put(3, 3); // evicts key 2
cache.get(2); // returns -1 (not found)
cache.get(3); // returns 3.
cache.put(4, 4); // evicts key 1.
cache.get(1); // returns -1 (not found)
cache.get(3); // returns 3
cache.get(4); // returns 4用类似LRU的方法,代码如下:
struct node {
node(int k, int v, int f) : key(k), value(v), freq(f) {}
int key,value,freq;
};
class LFUCache{ // 239 ms, Your runtime beats 24.26% of cpp submissions.
int capa_=0;
list<node> list_; // key, value
unordered_map<int, list<node>::iterator> map_; // key, list iterator
void update(int key, int value) { // Update (key, iterator of (key, value)) pair
int freq = 0;
auto lit = list_.begin();
auto mit = map_.find(key);
if (mit != map_.end()) {
freq = mit->second->freq;
lit = next(mit->second); // next iterator
list_.erase(mit->second);
}
++freq;
while (lit != list_.end() && freq >= lit->freq) // O(N)
++lit;
map_[key] = list_.emplace(lit, node(key, value, freq));
}
public:
LFUCache(int capacity) : capa_(capacity) {}
int get(int key) {
if (map_.count(key) && capa_) {
int t = map_[key]->value;
update(key, t);
return t;
}
return -1;
}
void put(int key, int value) {
if (!capa_) return;
// If cache is full while inserting, remove the last one.
if (list_.size() == capa_ && map_.count(key) == 0) {
node t = list_.front();
list_.pop_front(), map_.erase(t.key);
}
update(key, value);
}
};- Inserts a new element into the container directly before pos.
std::list::emplace(pos,...)- http://en.cppreference.com/w/cpp/container/list/emplace
和insert的相同和区别: http://en.cppreference.com/w/cpp/container/list/insert, 注意都是返回iterator.
上面的方法复杂度是\(O(N)\).显然还不是最优. 最优的方法在下面.
注意和LRU一样, get的时候freq要加1.
https://discuss.leetcode.com/topic/69402/c-list-with-hashmap-with-explanation
这个数据结构来自 LFU 的论文:lfu.pdf
Increasing frequencies
----------------------------->
+------+ +---+ +---+ +---+
| Head |----| 1 |----| 5 |----| 9 | Frequencies
+------+ +-+-+ +-+-+ +-+-+
| | |
+-+-+ +-+-+ +-+-+ |
|2,3| |4,3| |6,2| |
+-+-+ +-+-+ +-+-+ | Most recent
| | |
+-+-+ +-+-+ |
k,v pairs |1,2| |7,9| |
+---+ +---+ vSimilar to bucket sort, we place key,value pairs with the same frequency into the same bucket, within each bucket, the pairs are sorted according to most recent used, i.e., the one that is most recently used (set,get) is at the bottom of each bucket.
using KEY=int;
using VAL=int;
struct node {
int f;
list<pair<KEY,VAL>> kv; // node list
node(int f_=0) : f(f_) { }
};
using FITR=list<node>::iterator;// iterator of freq list
using NITR=list<pair<KEY,VAL>>::iterator; // iterator of node list
struct LFUCache { // Your runtime beats 92.89 % of cpp submissions.
private:
int cap_;
list<node> flist; // freq list
unordered_map<KEY, pair<FITR, NITR>> m; // key to two list iterators
pair<FITR, NITR> promote(int key, int val = -1) {
FITR i;
NITR j;
tie(i, j) = m[key];
FITR k = next(i);
if (val < 0) val = j->second;
int freq = i->f + 1;
i->kv.erase(j);
if (i->kv.empty()) flist.erase(i);
if (k == flist.end() || k->f != freq)
i = flist.insert(k, node(freq));
else
i = k;
j = i->kv.insert(i->kv.end(), {key, val});
return {i, j};
}
void evict() {
FITR i = flist.begin();
NITR j = i->kv.begin();
m.erase(j->first);
i->kv.erase(j);
if (i->kv.empty())
flist.erase(i);
}
pair<FITR, NITR> insert(int key, int val) {
FITR i = flist.begin();
if (i == flist.end() || i->f != 1)
i = flist.insert(i, node(1));
NITR j = i->kv.insert(i->kv.end(), {key, val});
return {i, j};
}
public:
LFUCache(int capacity) { cap_ = capacity; }
int get(int key) {
if (m.count(key)) {
m[key] = promote(key);
return m[key].second->second;
}
return -1;
}
void put(int key, int value) {
if (cap_ <= 0) return;
if (m.count(key)) {
m[key] = promote(key, value);
} else {
if (m.size() == cap_) evict();
m[key] = insert(key, value);
}
}
};这个代码使用了很多insert方法,比如insert方法其实可以这样写:
pair<FITR, NITR> insert(int key, int val) {
if(flist.empty() || flist.front().f>1)
flist.push_front(node(1));
flist.begin()->kv.emplace_back(key, val);
return {flist.begin(), prev(flist.front().kv.end())};
}http://en.cppreference.com/w/cpp/utility/tuple/tie
- JAVA
public class LFUCache {
HashMap<Integer, Integer> k2v; // kv
HashMap<Integer, Integer> k2f; // key to freq
HashMap<Integer, LinkedHashSet<Integer>> f2k; // freq list
int cap;
int min = -1;
public LFUCache(int capacity) {
cap = capacity;
k2v = new HashMap<>();
k2f = new HashMap<>();
f2k = new HashMap<>();
f2k.put(1, new LinkedHashSet<>());
}
public int get(int key) {
if(!k2v.containsKey(key))
return -1;
int count = k2f.get(key);
k2f.put(key, count+1);
f2k.get(count).remove(key); // remove key from current bucket (since we will inc count)
if(count==min && f2k.get(count).size()==0) // nothing in the current min bucket
min++;
if(!f2k.containsKey(count+1))
f2k.put(count+1, new LinkedHashSet<>());
f2k.get(count+1).add(key);
return k2v.get(key);
}
public void put(int key, int value) {
if(cap<=0)
return;
if(k2v.containsKey(key)) {
k2v.put(key, value); // update key's value
get(key); // update key's count
return;
}
if(k2v.size() >= cap) {
int evit = f2k.get(min).iterator().next();// get oldest one in bucket
f2k.get(min).remove(evit);
k2v.remove(evit);
k2f.remove(evit);//
}
k2v.put(key, value); // adding new key and count
k2f.put(key, 1);
min = 1;
f2k.get(1).add(key);
}
}At first I didn’t understand why we didn’t need to care about nextMin and we just could add 1 to min. Now it makes sense that min will always reset to 1 when adding a new item. And also, min can never jump forward more than 1 since updating an item only increments it’s count by 1.
LinkedHashSet介于HashSet与TreeSet之间.它由一个执行hash表的链表实现,因此,它提供顺序插入.基本方法的时间复杂度为O(1). Time complexity is better than C++’s set.
HashSet,TreeSet,LinkedHashSet的区别: http://blog.csdn.net/cynthia9023/article/details/17503023
http://wiki.jikexueyuan.com/project/java-collection/linkedhashset.html
24.3 432. All O(1) Data Structure
Implement a data structure supporting the following operations:
- Inc(Key) - Inserts a new key with value 1. Or increments an existing key by 1. Key is guaranteed to be a non-empty string.
- Dec(Key) - If Key’s value is 1, remove it from the data structure. Otherwise decrements an existing key by 1. If the key does not exist, this function does nothing. Key is guaranteed to be a non-empty string.
- GetMaxKey() - Returns one of the keys with maximal value. If no element exists, return an empty string "".
- GetMinKey() - Returns one of the keys with minimal value. If no element exists, return an empty string "".
Your AllOne object will be instantiated and called as such:
AllOne obj = new AllOne();
obj.inc(key);
obj.dec(key);
string param_3 = obj.getMaxKey();
string param_4 = obj.getMinKey();Challenge: Perform all these in O(1) time complexity.
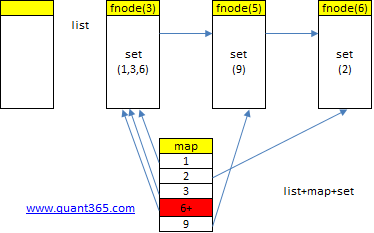
这道题其实是LFU的一个简化版.数据结构要简单一些,但是implementation其实更复杂,因为这里不但可以increase freq,还可以decrease freq.
increase的时候我们可以用end(),麻烦的是decrease的时候,如果当前node是begin(),我们不可以pass the begin.
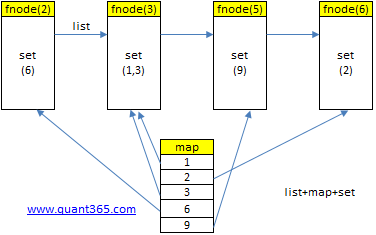
Inc:
https://leetcode.com/problems/all-oone-data-structure
struct node{
int f;
set<string> nset;
node(string& s,int f_):f(f_){nset.insert(s);}
};
class AllOne {
list<node> flist;
map<string, list<node>::iterator> m;
public:
AllOne() {}
void inc(string key) {
if(m.count(key)){
auto it=m[key];
it->nset.erase(key);
int f=it->f+1;
auto nx=next(it);
if(it->nset.empty()) flist.erase(it);
if(nx==flist.end() || f!=nx->f){
m[key]=flist.insert(nx, node(key, f));
}else{
nx->nset.insert(key);
m[key]=nx;
}
}else{
auto it=flist.begin();
if(flist.empty() || it->f!=1){
flist.push_front(node(key, 1));
m[key] = flist.begin();
}else
it->nset.insert(key), m[key]=it;
}
}
void dec(string key) {
if(!m.count(key)) return;
list<node>::iterator i=m[key];
if(i->f==1){
i->nset.erase(key);
if(i->nset.empty()) flist.erase(i);
m.erase(key);
}else{
int f=i->f;
if(i==flist.begin()){
i->nset.erase(key);
if(i->nset.empty()) flist.erase(i);
flist.push_front(node(key, f-1));
m[key]=flist.begin();
}else{
auto j=prev(i);
if(j->f == f-1){
i->nset.erase(key);
if(i->nset.empty()) flist.erase(i);
j->nset.insert(key), m[key]=j;
}else{
if(i->nset.size()==1){
i->f--;
}else{
i->nset.erase(key);
m[key]=flist.insert(i, node(key, f-1));
}
}
}
}
}
string getMaxKey() {
if(flist.empty()) return "";
return *flist.back().nset.rbegin();
}
string getMinKey() {
if(flist.empty()) return "";
return *flist.front().nset.begin();
}
};如果上面的set用unordered_set代替,getMaxKey就会出错,因为unordered_set不支持反向loop. 还有set可以保留插入顺序,替换之后不行.
- Why
std::prevdoes not fire an error with an iterator ofstd::unordered_set?: http://bit.ly/2xaNxzq - std::unordered_set does not support bidirectional iterators
- http://bit.ly/2xaQ9xc
24.4 362. Design Hit Counter
Design a hit counter which counts the number of hits received in the past 5 minutes.
Each function accepts a timestamp parameter (in seconds granularity) and you may assume that calls are being made to the system in chronological order (ie, the timestamp is monotonically increasing). You may assume that the earliest timestamp starts at 1.
It is possible that several hits arrive roughly at the same time.
Example:
HitCounter counter = new HitCounter();
// hit at timestamp 1.
counter.hit(1);
// hit at timestamp 2.
counter.hit(2);
// hit at timestamp 3.
counter.hit(3);
// get hits at timestamp 4, should return 3.
counter.getHits(4);
// hit at timestamp 300.
counter.hit(300);
// get hits at timestamp 300, should return 4.
counter.getHits(300);
// get hits at timestamp 301, should return 3.
counter.getHits(301); Follow up: What if the number of hits per second could be very large? Does your design scale?
https://leetcode.com/problems/design-hit-counter
这道题让我们设计一个点击计数器,能够返回五分钟内的点击数,提示了有可能同一时间内有多次点击.由于操作都是按时间顺序的,下一次的时间戳都会大于等于本次的时间戳,那么最直接的方法就是用一个队列queue,每次点击时都将当前时间戳加入queue中,然后在需要获取点击数时,我们从队列开头开始看,如果开头的时间戳在5分钟以外了,就删掉,直到开头的时间戳在5分钟以内停止,然后返回queue的元素个数即为所求的点击数,参见代码如下:
class HitCounter {
public:
HitCounter() {}
void hit(int timestamp) { // O(1)
q.push(timestamp);
}
int getHits(int timestamp) { // O(N)
while (!q.empty() && timestamp - q.front() >= 300) q.pop();
return q.size();
}
private:
queue<int> q;
};- JAVA
class HitCounter {
private Queue<Integer> q = null;
public HitCounter() {
q = new LinkedList();
}
public void hit(int timestamp) {
q.add(timestamp);
}
public int getHits(int timestamp) {
while(q.peek()!=null && timestamp>=300+q.peek()) q.remove();
return q.size();
}
}由于Follow up中说每秒中会有很多点击,下面这种方法就比较巧妙了,定义了1个大小为300的一维数组,保存时间戳和点击数,在点击函数中,将时间戳对300取余,然后看此位置中之前保存的时间戳和当前的时间戳是否一样,一样说明是同一个时间戳,那么对应的点击数自增1,如果不一样,说明已经过了五分钟了,那么将对应的点击数重置为1.那么在返回点击数时,我们需要遍历times数组,找出所有在5分中内的位置,然后把hits中对应位置的点击数都加起来即可,参见代码如下:
class HitCounter {
vector<pair<int,int>> v;
static const int WINLEN=300;
public:
HitCounter() {v.resize(WINLEN);}
void hit(int timestamp) {
auto& node=v[timestamp%WINLEN];
if(node.first==timestamp) node.second++;
else node.first=timestamp, node.second=1;
}
int getHits(int timestamp) {
int sum=0;
for(auto& node:v) // 0-299 is valid, 300 isn't, so cannot use ==
if(node.first+WINLEN>timestamp) sum+=node.second;
return sum;
}
};24.5 359. Logger Rate Limiter
Design a logger system that receive stream of messages along with its timestamps, each message should be printed if and only if it is not printed in the last 10 seconds.
Given a message and a timestamp (in seconds granularity), return true if the message should be printed in the given timestamp, otherwise returns false.
It is possible that several messages arrive roughly at the same time.
Example:
Logger logger = new Logger();
// logging string "foo" at timestamp 1
logger.shouldPrintMessage(1, "foo"); returns true;
// logging string "bar" at timestamp 2
logger.shouldPrintMessage(2,"bar"); returns true;
// logging string "foo" at timestamp 3
logger.shouldPrintMessage(3,"foo"); returns false;
// logging string "bar" at timestamp 8
logger.shouldPrintMessage(8,"bar"); returns false;
// logging string "foo" at timestamp 10
logger.shouldPrintMessage(10,"foo"); returns false;
// logging string "foo" at timestamp 11
logger.shouldPrintMessage(11,"foo"); returns true;https://leetcode.com/problems/logger-rate-limiter/
class Logger {
map<string,int> m; // string to current(last) print time
public:
Logger() {}
bool shouldPrintMessage(int timestamp, string message) {
if (!m.count(message) || (timestamp - m[message] >= 10)){
m[message] = timestamp;
return true;
}
return false;
}
};- Java Circular Buffer Solution, similar to
Hit Counter
public class Logger {
private int[] buckets = new int[10]; //store timestamp
private Set[] sets = new Set[10]; // id to Strings printed in last 10s
public Logger() {
for (int i = 0; i < sets.length; ++i)
sets[i] = new HashSet<String>();
}
public boolean shouldPrintMessage(int timestamp, String message) {
int idx = timestamp % 10;
if (timestamp != buckets[idx]) { // old data or no data ever
sets[idx].clear();
buckets[idx] = timestamp;
}
for (int i = 0; i < buckets.length; ++i) {
if (timestamp - buckets[i] < 10 &&
sets[i].contains(message)) return false;
}
sets[idx].add(message);
return true;
}
}24.6 555. Counting Bloom Filter
Implement a counting bloom filter. Support the following method:
- add(string). Add a string into bloom filter.
- contains(string). Check a string whether exists in bloom filter.
- remove(string). Remove a string from bloom filter.
Example
CountingBloomFilter(3)
add("lint")
add("code")
contains("lint") // return true
remove("lint")
contains("lint") // return falsehttp://www.lintcode.com/en/problem/counting-bloom-filter/
除了存在false positive这个问题之外,传统的Bloom Filter还有一个不足:无法支持删除操作(想想看,是不是这样的).而Counting Bloom Filter(CBF)就是用来解决这个问题的.
http://www.yebangyu.org/blog/2016/01/23/insidethebloomfilter/
class HashFunction {
private:
int cap, seed;
public:
HashFunction(int cap, int seed) {
this->cap = cap;
this->seed = seed;
}
int hash(string& value) {
int ret = 0;
int n = value.size();
for (int i = 0; i < n; ++i) {
ret += seed * ret + value[i];
ret %= cap;
}
return ret;
}
};
class CountingBloomFilter {
public:
CountingBloomFilter(int k) {
this->k = k;
for (int i = 0; i < k; ++i) {
hashFunc.push_back(new HashFunction(100000 + i, 2 * i + 3));
}
bits.resize(100000 + k);
}
void add(string& word) {
for (int i = 0; i < k; ++i) {
int position = hashFunc[i]->hash(word);
++bits[position];
}
}
void remove(string& word) {
for (int i = 0; i < k; ++i) {
int position = hashFunc[i]->hash(word);
--bits[position];
}
}
bool contains(string& word) {
for (int i = 0; i < k; ++i) {
int position = hashFunc[i]->hash(word);
if (bits[position] <= 0) {
return false;
}
}
return true;
}
private:
int k;
vector<HashFunction*> hashFunc;
vector<int> bits;
};24.7 556. Standard Bloom Filter
Implement a standard bloom filter. Support the following method:
- StandardBloomFilter(k),The constructor and you need to create k hash functions.
- add(string). add a string into bloom filter.
- contains(string). Check a string whether exists in bloom filter.
Example
StandardBloomFilter(3)
add("lint")
add("code")
contains("lint") // return true
contains("world") // return falsehttp://www.lintcode.com/en/problem/standard-bloom-filter/
#include<bitset>
#define LEN 200000
class HashFunction {
private:
int cap, seed;
public:
HashFunction(int cap_, int seed_): cap(cap_), seed(seed_) {}
int hash(string& value) {
int ret = 0, n = value.size();
for (int i = 0; i < n; ++i) {
ret += seed * ret + value[i];
ret %= cap;
}
return ret;
}
};
class StandardBloomFilter {
public:
StandardBloomFilter(int k) {
while(k--)
hashFunc.push_back(HashFunction(LEN-k, 2*k+3));
}
void add(string& word) {
for (auto h: hashFunc)
bits.set(h.hash(word));
}
bool contains(string& word) {
for (auto h: hashFunc)
if (!bits.test(h.hash(word))) return false;
return true;
}
private:
vector<HashFunction> hashFunc;
bitset<LEN> bits;
};http://www.cnblogs.com/heaad/archive/2011/01/02/1924195.html
import java.util.BitSet;
public class BloomFilter{
/* BitSet初始分配2^24个bit */
private static final int DEFAULT_SIZE =1<<25;
/* 不同哈希函数的种子,一般应取质数 */
private static final int[] seeds =newint[] { 5, 7, 11, 13, 31, 37, 61 };
private BitSet bits =new BitSet(DEFAULT_SIZE);
/* 哈希函数对象 */
private SimpleHash[] func =new SimpleHash[seeds.length];
public BloomFilter(){
for (int i =0; i < seeds.length; i++){
func[i] =new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
// 将字符串标记到bits中
public void add(String value){
for (SimpleHash f : func)
bits.set(f.hash(value), true);
}
//判断字符串是否已经被bits标记
public boolean contains(String value){
if (value ==null){
returnfalse;
}
boolean ret =true;
for (SimpleHash f : func){
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/* 哈希函数类 */
public static class SimpleHash{
private int cap;
private int seed;
public SimpleHash(int cap, int seed){
this.cap = cap;
this.seed = seed;
}
//hash函数,采用简单的加权和hash
public int hash(String value){
int result =0;
int len = value.length();
for (int i =0; i < len; i++)
result = seed * result + value.charAt(i);
return (cap -1) & result;
}
}
}24.8 635. Design Log Storage System
You are given several logs that each log contains a unique id and timestamp. Timestamp is a string that has the following format: Year:Month:Day:Hour:Minute:Second, for example, 2017:01:01:23:59:59. All domains are zero-padded decimal numbers.
Design a log storage system to implement the following functions:
void Put(int id, string timestamp): Given a log’s unique id and timestamp, store the log in your storage system.
int Retrieve(String start, String end, String granularity): Return the id of logs whose timestamps are within the range from start to end. Start and end all have the same format as timestamp. However, granularity means the time level for consideration. For example, start = “2017:01:01:23:59:59”, end = “2017:01:02:23:59:59”, granularity = “Day”, it means that we need to find the logs within the range from Jan. 1st 2017 to Jan. 2nd 2017.
Example 1:
put(1, "2017:01:01:23:59:59");
put(2, "2017:01:01:22:59:59");
put(3, "2016:01:01:00:00:00");
// return [1,2,3], because you need to return all logs within 2016 and 2017.
retrieve("2016:01:01:01:01:01","2017:01:01:23:00:00","Year");
// return [1,2], because you need to return all logs start from 2016:01:01:01 to
// 2017:01:01:23, where log 3 is left outside the range.
retrieve("2016:01:01:01:01:01","2017:01:01:23:00:00","Hour"); Note:
There will be at most 300 operations of Put or Retrieve.
Year ranges from [2000,2017]. Hour ranges from [00,23].
Output for Retrieve has no order required.https://leetcode.com/problems/design-log-storage-system/
这道题让我们设计一个日志存储系统,给了日志的生成时间和日志编号,日志的生成时间是精确到秒的,然后我们主要需要完成一个retrieve函数,这个函数会给一个起始时间,结束时间,还有一个granularity精确度,可以精确到任意的年月日时分秒,可以分析下题目中的例子,应该不难理解.我们首先需要一个数据结构来存储每个日志的编号和时间戳,那么这里我们就用一个数组,里面存pair,这样就能存下日志的数据了.然后由于我们要用到精确度,所以我们用一个units数组来列出所有可能的精确度了.下面就是本题的难点了,如何能正确的在时间范围内取出日志.由于精确度的存在,比如精确度是Day,那么我们就不关心后面的时分秒是多少了,只需要比到天就行了.判断是否在给定的时间范围内的方法也很简单,看其是否大于起始时间,且小于结束时间,我们甚至可以直接用字符串相比较,不用换成秒啥的太麻烦.所以我们可以根据时间精度确定要比的子字符串的位置,然后直接相比就行了.所以我们需要一个indices数组,来对应我们的units数组,记录下每个时间精度下取出的字符的个数.然后在retrieve函数中,遍历所有的日志,快速的根据时间精度取出对应的时间戳并且和起始结束时间相比,在其之间的就把序号加入结果res即可.
class LogSystem {
public:
LogSystem() {
units = {"Year", "Month", "Day", "Hour", "Minute", "Second"};
indices = {4, 7, 10, 13, 16, 19};
}
void put(int id, string timestamp) {
timestamps.push_back({id, timestamp});
}
vector<int> retrieve(string s, string e, string gra) {
vector<int> res;
int idx = indices[find(units.begin(), units.end(), gra) - units.begin()];
for (auto p : timestamps) {
string t = p.second;
if (t.substr(0, idx).compare(s.substr(0, idx)) >= 0 && t.substr(0, idx).compare(e.substr(0, idx)) <= 0) {
res.push_back(p.first);
}
}
return res;
}
private:
vector<pair<int, string>> timestamps;
vector<string> units;
vector<int> indices;
};24.9 588. Design In-Memory File System
Design an in-memory file system to simulate the following functions:
ls: Given a path in string format. If it is a file path, return a list that only contains this file’s name. If it is a directory path, return the list of file and directory names in this directory. Your output (file and directory names together) should in lexicographic order.
mkdir: Given a directory path that does not exist, you should make a new directory according to the path. If the middle directories in the path don’t exist either, you should create them as well. This function has void return type.
addContentToFile: Given a file path and file content in string format. If the file doesn’t exist, you need to create that file containing given content. If the file already exists, you need to append given content to original content. This function has void return type.
readContentFromFile: Given a file path, return its content in string format.
Example:
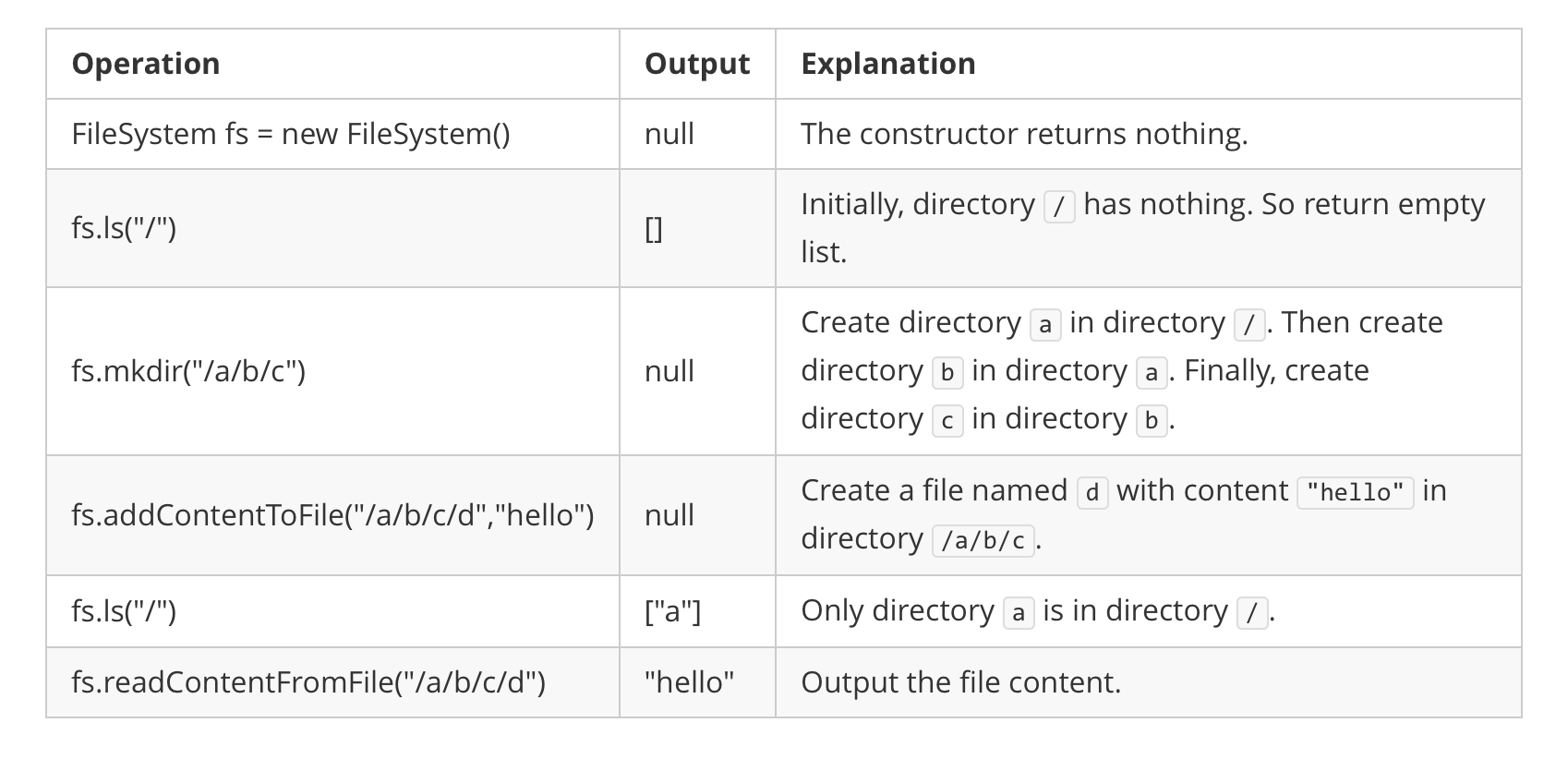
Input:
["FileSystem","ls","mkdir","addContentToFile","ls","readContentFromFile"]
[[],["/"],["/a/b/c"],["/a/b/c/d","hello"],["/"],["/a/b/c/d"]]Output:
[null,[],null,null,["a"],"hello"]Explanation:
filesystem
Note:
You can assume all file or directory paths are absolute paths which begin with / and do not end with / except that the path is just “/”.
You can assume that all operations will be passed valid parameters and users will not attempt to retrieve file content or list a directory or file that does not exist.
You can assume that all directory names and file names only contain lower-case letters, and same names won’t exist in the same directory.
这道题让我们设计一个内存文件系统,实现显示当前文件,创建文件,添加内容到文件,读取文件内容等功能,感觉像是模拟一个terminal的一些命令.这道题比较tricky的地方是ls这个命令,题目中的例子其实不能很好的展示出ls的要求,其对文件和文件夹的处理方式是不同的.由于这里面的文件没有后缀,所以最后一个字符串有可能是文件,也有可能是文件夹.比如a/b/c,那么最后的c有可能是文件夹,也有可能好是文件,如果c是文件夹的话,ls命令要输出文件夹c中的所有文件和文件夹,而当c是文件的话,只需要输出文件c即可.另外需要注意的是在创建文件夹的时候,路径上没有的文件夹都要创建出来,还有就是在给文件添加内容时,路径中没有的文件夹都要创建出来.论坛上这道题的高票解法都新建了一个自定义类,但是博主一般不喜欢用自定义类来解题,而且感觉那些使用了自定义类的解法并没有更简洁易懂,所以这里博主就不创建自定义类了,而是使用两个哈希表来做,其中dirs建立了路径和其对应的包含所有文件和文件夹的集合之间的映射,files建立了文件的路径跟其内容之间的映射.
最开始时将根目录“/”放入dirs中,然后看ls的实现方法,如果该路径存在于files中,说明最后一个字符串是文件,那么我们将文件名取出来返回即可,如果不存在,说明最后一个字符串是文件夹,那么我们到dirs中取出该文件夹内所有的东西返回即可.再来看mkdir函数,我们的处理方法就是根据“/”来分隔分隔字符串,如果是Java,那么直接用String自带的split函数就好了,但是C++没有Java那么多自带函数,所以只能借助字符串流类来处理,处理方法就是将每一层的路径分离出来,然后将该层的文件或者文件夹加入对应的集合中,注意的地方就是处理根目录时,要先加上“/”,其他情况都是后加.下面来看addContentToFile函数,首先分离出路径和文件名,如果路径为空,说明是根目录,需要加上“/”,然后看这个路径是否已经在dirs中存在,如果不存在,调用mkdir来创建该路径,然后把文件加入该路径对应的集合中,再把内容加入该文件路径的映射中.最后的读取文件内容就相当简单了,直接在files中返回即可,参见代码如下
class FileSystem {
public:
FileSystem() {
dirs["/"];
}
vector<string> ls(string path) {
if (files.count(path)) {
int idx = path.find_last_of('/');
return {path.substr(idx + 1)};
}
auto t = dirs[path];
return vector<string>(t.begin(), t.end());
}
void mkdir(string path) {
istringstream is(path);
string t = "", dir = "";
while (getline(is, t, '/')) {
if (t.empty()) continue;
if (dir.empty()) dir += "/";
dirs[dir].insert(t);
if (dir.size() > 1) dir += "/";
dir += t;
}
}
void addContentToFile(string filePath, string content) {
int idx = filePath.find_last_of('/');
string dir = filePath.substr(0, idx);
string file = filePath.substr(idx + 1);
if (dir.empty()) dir = "/";
if (!dirs.count(dir)) mkdir(dir);
dirs[dir].insert(file);
files[filePath].append(content);
}
string readContentFromFile(string filePath) {
return files[filePath];
}
private:
unordered_map<string, set<string>> dirs;
unordered_map<string, string> files;
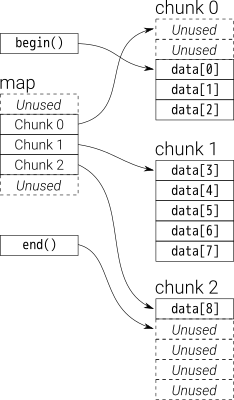
};24.10 Unrolled Linked List
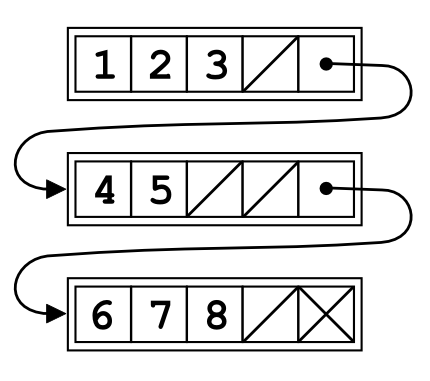
indeed.html#unrolled-linked-list-1
https://www.geeksforgeeks.org/unrolled-linked-list-set-1-introduction/