Chapter 54 Linkedin 2017 Interview Questions Part 1

54.3 Top K URLs in last 24hr/1hr/5min
http://www.1point3acres.com/bbs/thread-218646-1-1.html
时间的限制我意思是给每一条记录在内存里面加上有效时间,好像叫TTL time to live,这样来统计last 5min/1hr的频率
https://github.com/facebook/folly/blob/master/folly/stats/MultiLevelTimeSeries.h ?
This class represents a timeseries which keeps several levels of data granularity (similar in principle to the loads reported by the UNIX ‘uptime’ command). It uses several instances (one per level) of BucketedTimeSeries as the underlying storage.
This can easily be used to track
sums(and thusratesoraverages) over severalpredetermined time periods, as well as all-time sums. For example, you would use to it to trackquery rateorresponse speedoverthe last 5, 15, 30, and 60 minutes.The MultiLevelTimeSeries takes a list of level durations as an input; the durations must be strictly increasing. Furthermore a special level can be provided with a duration of ‘0’ – this will be an “all-time” level. If an all-time level is provided, it MUST be the last level present.
The class assumes that
time advances forward– you can’t retroactively add values for events in the past – the ‘now’ argument is provided for better efficiency and ease of unittesting.
The class is not thread-safe – use your own synchronization!
http://stackoverflow.com/questions/10189685/realtime-tracking-of-top-100-twitter-words-per-min-hour-day
http://stackoverflow.com/questions/14117332/find-top-k-visiting-url-for-last-day-or-last-hour-or-last-minute
 follow up是怎么保证对全球各地用户的响应速度
follow up是怎么保证对全球各地用户的响应速度
##Design Spellchecker
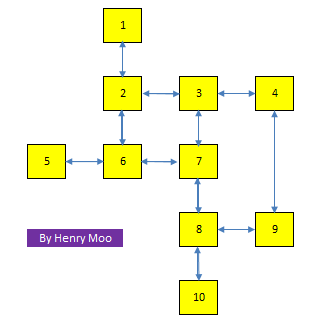
54.4 Flatten a multilevel linked list 2
Check: linkedin-before-2015

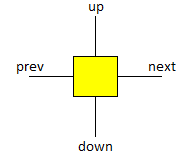
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=222643
public class MultiListToDoubleList {
static class MultiListNode {
int val;
MultiListNode pre;
MultiListNode next;
MultiListNode up;
MultiListNode down;
}
public static void convert(MultiListNode head) {
if (head == null) { return; }
MultiListNode tail = head;
while (tail.next != null) { tail = tail.next; }
MultiListNode cur = head;
while (cur != null) {
if (cur.up != null) {
tail.next = cur.up;
cur.up.pre = tail;
while (tail.next != null) { tail = tail.next; }
cur.up = null;
}
if (cur.down != null) {
tail.next = cur.down;
cur.down.pre = tail;
while (tail.next != null) { tail = tail.next; }
cur.down = null;
}
cur = cur.next;
}
}
}
54.5 380. Insert Delete GetRandom O(1)
https://leetcode.com/problems/insert-delete-getrandom-o1/
class RandomizedSet { // 96%
map<int, int> m; // value to index
vector<int> v;
public:
/** Initialize your data structure here. */
RandomizedSet() {}
/** Inserts a value to the set. Returns true if the
set did not already contain the specified element. */
bool insert(int val) { // 从tail插入
if(m.count(val)) return false;
v.push_back(val);
m[val] = v.size()-1;
return true;
}
/** Removes a value from the set. Returns true if the
set contained the specified element. */
bool remove(int val) { // remove according to value
if(m.count(val)==0) return false;
int i=m[val];
m[v.back()]=i;////
swap(v[i], v.back());
v.pop_back();
m.erase(val);
return true;
}
/** Get a random element from the set. */
int getRandom() {
return v[rand()%v.size()];
}
};底层数据结构是: vector + index map
一个类似的题,pop_from_top(), pop_from_tail(), get_random(),get_index(i)全部O(1),可以用circular buffer来做.
54.5.1 381. Insert Delete GetRandom O(1) - Duplicates allowed
https://leetcode.com/problems/insert-delete-getrandom-o1-duplicates-allowed/
http://www.1point3acres.com/bbs/thread-223433-1-1.html
查询还是直接操作vector没有难度.而插入的时候,是插入到位置集合也没有难度.
问题在于删除.删除的时候,idea和之前380一样,同样是将vector的最后一个交换到前面,但是现在一个值有多个位置,所以最后那个值可能和要删除的值相同.
class RandomizedCollection {
private:
unordered_map<int, unordered_set<int>> index;
vector<int> output;
public:
/** Initialize your data structure here. */
RandomizedCollection() {}
/** Inserts a value to the collection. Returns true if the
collection did not already contain the specified element. */
bool insert(int val) {
bool return_val = index.find(val) == index.end();
index[val].insert(output.size());
output.push_back(val);
return return_val;
}
/** Removes a value from the collection. Returns true if the
collection contained the specified element. */
bool remove(int val) {
if (index.find(val) == index.end()) return false;
int last = output.back(); output.pop_back();
index[last].erase(output.size());
if (last != val) {
int _id = *index[val].begin(); index[val].erase(_id);
index[last].insert(_id);
output[_id] = last;
}
if (index[val].empty())
index.erase(val);
return true;
}
/** Get a random element from the collection. */
int getRandom() {
return output[rand() % output.size()];
}
};注意:
unordered_set就算integer,也不能保证从小到大的顺序.请看:
[cling]$ #include <unordered_set>
[cling]$ #include <iostream>
[cling]$ using namespace std;
[cling]$ unordered_set<int> ui;
[cling]$ ui.insert(1);
[cling]$ ui.insert(2);
[cling]$ ui.insert(3);
[cling]$ ui.insert(4);
[cling]$ ui.insert(5);
[cling]$ ui.insert(6);
[cling]$ for(auto i: ui) cout << i<< endl;
6
5
1
2
3
454.6 Tournament Tree

Tournament tree 找secMin;
Tournament tree 的定义是parent 是孩子node的最小值, 如下例 return 5
2
/ \
2 7
/ \ | \
5 2 8 7http://www.1point3acres.com/bbs/thread-218356-1-1.html
http://www.1point3acres.com/bbs/thread-141428-1-1.html
http://stackoverflow.com/questions/3628718/find-the-2nd-largest-element-in-an-array-with-minimum-number-of-comparisons/3628777#3628777
int second_minimum(Node* R){
if (R==0 || (R->left==0 && R->right==0)) return -1;
int c1=-1, c2=-1; // candidate 1 and 2
if(R->left->val == R->val){
c1 = second_minimum(R->left);
c2 = R->right;
}
if(R->right->val == R->val){
c1 = second_minimum(R->right);
c2 = R->left;
}
if(c1==-1) return c2; else return min(c1,c2);
}下面是一个find second smallest的implementation:
#define MIN(x,y) min((x),(y));count++;
class SecondSmallest {
vector<vector<int>> _cache;
int count = 0;
const vector<int> v;
SecondSmallest(const vector<int>& _v) :v(_v) {
_cache = vector<vector<int>>(v.size(), vector<int>(v.size(), INT_MAX));
}
int _2ndsmallest(int h, int t) {
if (t - h == 1) return v.front();
if (t - h == 2) {
int r = MIN(v[0], v[1]);
return r;
}
int c1 = INT_MAX, c2 = INT_MAX;
int R = smallest(h, t);
int m = h + (t - h) / 2;
if (R == smallest(h, m)) {
c1 = _2ndsmallest(h, m);
c2 = smallest(m + 1, t);
} else if (R == smallest(m + 1, t)) {
c1 = _2ndsmallest(m + 1, t);
c2 = smallest(h, m);
}
if (c1 == INT_MAX) return c2;
int r = MIN(c1, c2);
return r;
}
int smallest(int h, int t) {
if (_cache[h][t] != INT_MAX) { return _cache[h][t]; }
if (h == t) return v[h];
_cache[h][t] = MIN(smallest(h, h + (t - h) / 2),
smallest(h + (t - h) / 2 + 1, t));
return _cache[h][t];
}
public:
int _2ndsmallest() { return _2ndsmallest(0, v.size() - 1); }
int smallest() { return smallest(0, v.size() - 1); }
};count是比较的次数,可以验证CLRS p215的结果, comparison times = \(N + ceil(log_2N) -2\)!!!
这个是用的top down的方法,所以用了_cache用类似DP的思想避免重复计算. 如果bottom up要建树winner tree, 太麻烦了. 参考: http://www.geeksforgeeks.org/second-minimum-element-using-minimum-comparisons/
54.7 Float to English Words
查看这个: facebook-2017-01
http://www.voidcn.com/blog/proudmore/article/p-3568732.html
- how to get top 10 Exceptions for the past 24 hours in 400 machines and update every 5 minutes. General idea: Kafka + Storm. Uses sliding window, hashTable, heap. (这道题pinterest也问了)

54.8 Print Matrix
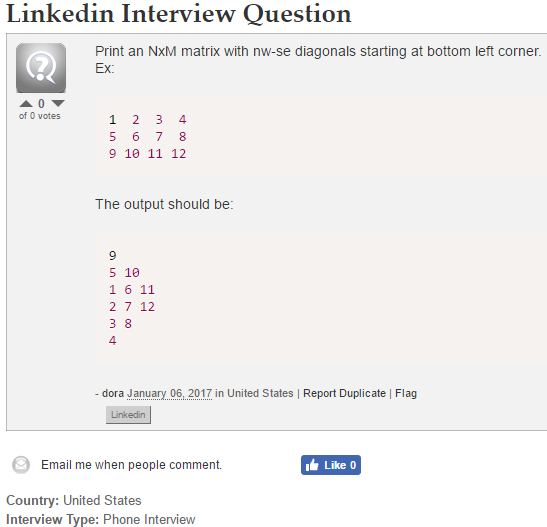
void NW2SE(vector<vector<int>> v) {
int ROW = v.size(), COL = v[0].size();
int i = ROW - 1;
while (i>=0) {
int k = i, j=0;
while(k<ROW && j<COL) cout << v[k++][j++] << " ";
i--;
cout << endl;
}
int j = 1;
while (j < COL) {
int k = j, i = 0;
while (k<COL && i<ROW) cout << v[i++][k++] << " ";
j++;
cout << endl;
}
}话说我在Bloomberg面试的时候也遇到这个题,很简单.
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=224154
Check: array
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=225081
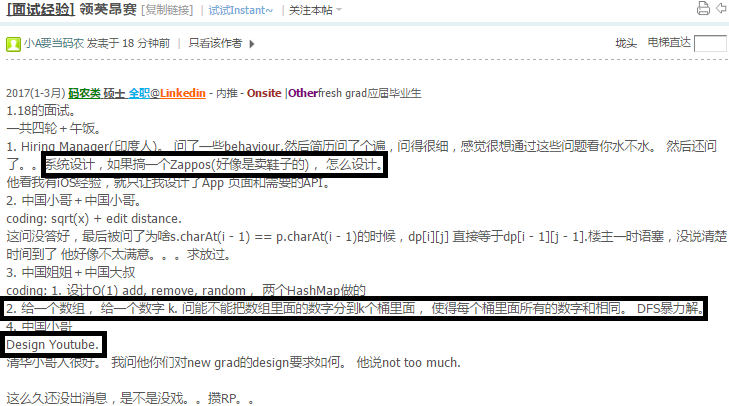
54.9 Evely Split N numbers into K buckets + Desgin Youtube + Zappos
比如 [1,2,3,4,5,6,7,8] 要放到3个buckets里面使每个bucket的数字的和相等.
那么每个bucket的数字和肯定是36/3=12.
bool dfs(vector<int>& v, int total, int target, vector<bool>& bm, int n)
{
if(total<0) return false;
if(total==0){
if(n==0){
return true;
}else total=target;
}
for(int i=0;i<v.size();++i){
if(!bm[i]){
bm[i]=true;
if (dfs(v,total-v[i],target,bm,n-1)) return true;
bm[i]=false;
}
}
return false;
}
bool EvenSplit(vector<int>& v, int k){
int sum=0;
for(int i:v) sum+=i;
if(sum%k!=0) return false;
int total=sum/k;
vector<bool> bm(v.size(),false);
return dfs(v, total, total, bm, v.size());
}注意分法不是唯一的,比如上面的例子,可以分成(5,7)+(4,8)+(2,3,6), 也可以分成(5,7)+(1,3,8)+(2,4,6)
但是这个题目只要求返回true or false.所以DFS就解决了.
完整代码: https://repl.it/F0az
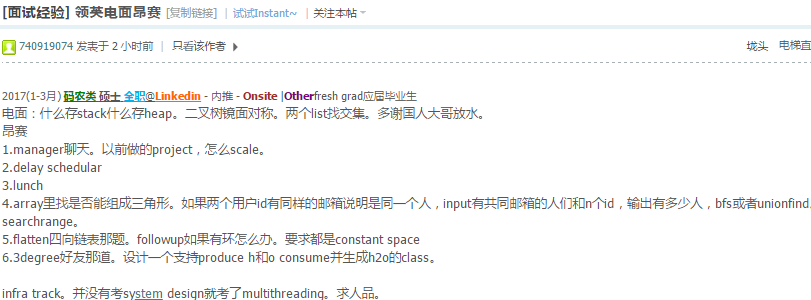
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=225497
http://www.1point3acres.com/bbs/thread-227298-1-1.html
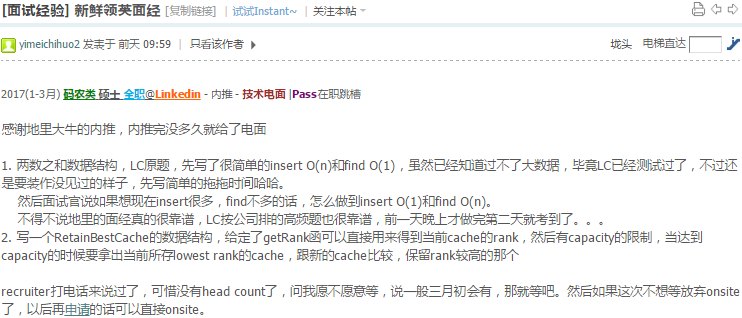
不好意思我没说清楚,题目不要求找到最高rank的,只要求实现get跟set,然后getRank是给定了可以直接用.在没有达到capacity的情况下只需要insert到minheap就好,如果达到了capacity就拿出lowest rank cache跟新来的cache比较,保留较大的,所以会是O(logn).还需要一个hash map,每次insert到minheap的时候也要存入hash map,这样可以做到get的时候是O(1).
indexheap ?
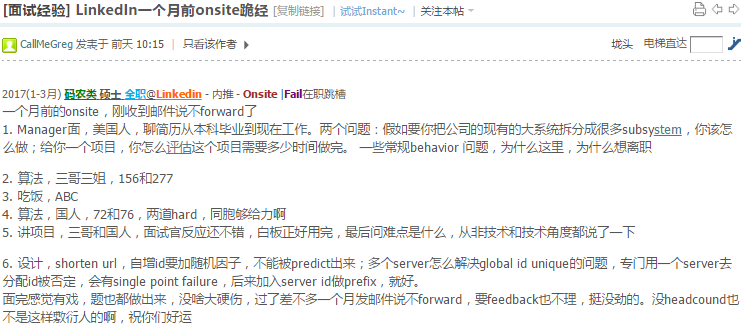
54.11 Hangman
樓主可不可以說說hangman的要求 跟怎麼design的?
先问一些基本的你整个system有些什么功能,如果开始是一个单个用户怎么设计,像client side server side怎么设计,用户log in的时候你怎么处理. 然后扩展到需要scale,然后就是基本数据库啊什么的
 规则里面有值得注意的地方.比如猜hello,猜中了l之后,两个l都会立刻显示!还是只显示一个l,这个是需要给interviewer先搞清楚.
规则里面有值得注意的地方.比如猜hello,猜中了l之后,两个l都会立刻显示!还是只显示一个l,这个是需要给interviewer先搞清楚.

还有就是猜了的单词不能再用了.比如上图,猜BEEN,猜了E之后下面的备选字母就没有E了,不能再猜.
$python hangman2.py
Loading word list from file...
1 words loaded.
Welcome to the game, Hangman!
I am thinking of a word that is 5 letters long.
------------
You have 8 guesses left.
Available letters: abcdefghijklmnopqrstuvwxyz
Please guess a letter: h
Good guess: h____
------------
You have 8 guesses left.
Available letters: abcdefgijklmnopqrstuvwxyz
Please guess a letter: l
Good guess: h_ll_
------------
You have 8 guesses left.
Available letters: abcdefgijkmnopqrstuvwxyz
Please guess a letter:游戏其实分为很多类型single user game, MMORPG(Massively multiplayer online role-playing game). 首先从简单情况入手
- Offline Single User Game
单用户单机版离线游戏(可以理解为离线的单机版,而且是一个用户和机器对战).这是最简单的情况.没什么考的.
主要是数据库设计,还有游戏信息保存和恢复.
不需要client-server设计, 用户名甚至都不需要, 唯一需要的是单词库和逻辑. 单词库可以存在一个简单的文件里面. 单机版的逻辑有两个例子请看这里:
- hangmang1
- hangman2
数据结构:
- Multiple Users Game
多用户,CS模式的设计,就需要数据库了.下面是一种数据库设计:
from google.appengine.ext import ndb
from google.appengine.ext.ndb import msgprop
from protorpc import messages
class GameStatus(messages.Enum):
"""Game Statuses Enum"""
IN_SESSION = 1
WON = 2
LOST = 3
ABORTED = 4
class User(ndb.Model):
"""User Profile"""
user_name = ndb.StringProperty(required=True)
email = ndb.StringProperty(required=True)
display_name = ndb.StringProperty()
mu = ndb.FloatProperty(required=True)
sigma = ndb.FloatProperty(required=True)
class Game(ndb.Model):
"""Game Model"""
game_id = ndb.IntegerProperty(required=True)
game_name = ndb.StringProperty() #optional
word = ndb.StringProperty(required=True)
guessed_chars_of_word = ndb.StringProperty(repeated=True)
guesses_left = ndb.IntegerProperty(default=6)
game_over = ndb.BooleanProperty(default=False)
game_status = msgprop.EnumProperty(GameStatus, default=GameStatus.IN_SESSION)
timestamp = ndb.DateTimeProperty(required=True, auto_now=True)
class Score(ndb.Model):
"""Score Model"""
score_id = ndb.IntegerProperty(required=True)
game_key = ndb.KeyProperty(required=True, kind='Game')
timestamp = ndb.DateTimeProperty(required=True, auto_now_add=True)
game_score = ndb.IntegerProperty(required=True, default=0)
class GameHistory(ndb.Model):
"""Game History Model"""
step_timestamp = ndb.DateTimeProperty(required=True, auto_now_add=True)
step_char = ndb.StringProperty()
game_snapshot = ndb.StructuredProperty(Game)The new feature we can add is a ranking system which rank users according to their scores.
When user plays game, he can earn score for each game.
word存在本地,用javascript或者jar运行在本地.如果游戏正常结束,把分数送回服务器;如果游戏被abort,就把历史记录送回服务器.这个有很大的安全问题,所以一般不会采用,就开始讨论下开拓思路.
word存在服务器端,这个设计比较靠谱.
设计需求
(1). leaderboard
TopK players by scores
(2). all game history for one user
User: henrymoo TotalScore: 123.56
| word | mistakes | score | time | status |
--------------------------------------------
| hello| 2 | 12 | 2min | won |
| world| 3 | 15 | 1min | lost |
| wheel| 4 | 2 | 1min | aborted|MVC和RESTFUL的web设计.
http://blog.csdn.net/shawndong/article/details/45023081
API的身份认证应该使用OAuth 2.0框架. OAuth说明: http://www.ruanyifeng.com/blog/2014/05/oauth_2_0.html
- 如果用户正在玩的时候断网了怎么办?
对TCP连接的客户端,如果断网: http://www.cnblogs.com/youxin/p/4056041.html
Keep alive VS Heart beat
网页游戏都有哪些安全问题?如何做得更安全?
https://www.zhihu.com/question/21753755
网页游戏分两类:flash游戏与html游戏.
flash游戏与服务端通信的消息格式有两类:
- 是flash特有的amf消息格式.这个格式是可逆的,一般外挂就会逆出这个格式,然后自动化.
- http协议,这个导致的服务端安全问题和普通的网站基本没什么区别,因为此时服务端都是nginx, lighttp, apache, tomcat之类,服务端语言是:php, java, python之类.我遇到的一些flash游戏,相关逻辑在客户端进行,缺乏服务端验证,直接导致我可以无限金币,无限装备…开发者以为flash那么厚,看不到运算逻辑,实际上要反编译出源码很容易,比如用swfscan,很多时候的攻击直接在浏览器中间人抓包拦截,就更容易了:)
html游戏这个和服务端通信就是http了,如果用了html5,也许会用websocket.不过一般都是http协议,所以服务端安全问题和普通网站没什么区别.由于是html,在客户端上还可能出现XSS, CSRF等问题,这类客户端安全问题可能导致用户账号被劫持等问题.整体来说,搞网页游戏的攻击成本更低.
5M DAU, 20 games per user on average, so totally 100M new rows in
gametable per day.
如果这样话,我们不应该把单词string放在game table里面.英文单词总共才十几万个吧(Oxford English Dictionary).
这样我们得加一个word table.
如果采用关系数据库的设计模式,应该是这样的图:
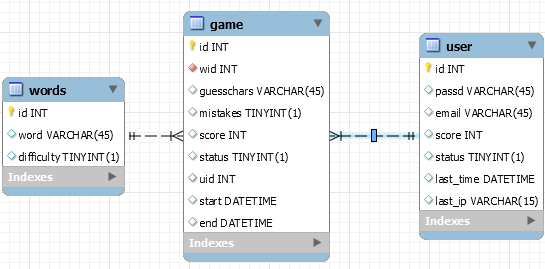
- Score怎么算?
我们可以根据字典统计出每个字母出现的频率,频率越低的难度越高.但是这并不代表就一定难猜. 比如zoo,猜出了oo之后,z就非常容易猜出来. 我们可以把这个作为初始的难度值.
difficulty = (1-percentage of frequency) * len(word)然后我们可以根据大量用户的猜测结果来修正这个难度值.
如何查看最难的单词topK?或者最被容易猜错的单词topK?
- DB Sharding
每天一亿行数据,太大了必须分区sharding.运行10年,就是3650忆 = 365B行. 这种情况一定是选NoSQL.
Which database could handle storage of billions/trillions of records?
http://dba.stackexchange.com/questions/38793/which-database-could-handle-storage-of-billions-trillions-of-records
到底选哪个数据库呢?
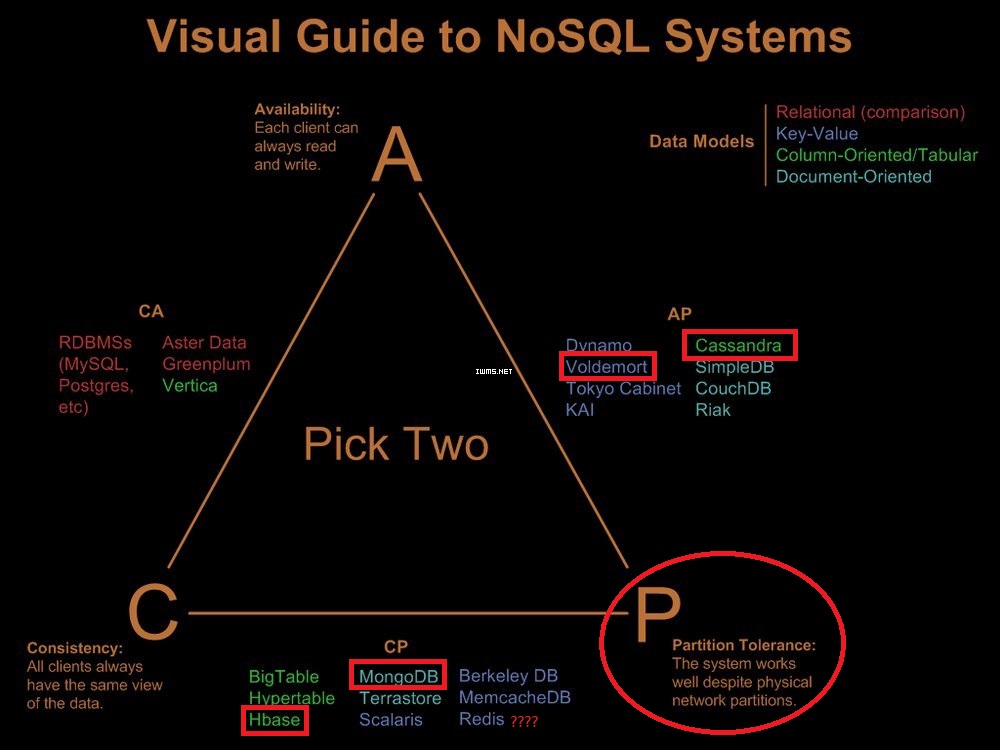
Check: NoSQL选型及HBase案例详解
http://www.cnblogs.com/stubborn412/p/3958616.html
NoSQL一定程度上是基于一个很重要的原理—— CAP原理提出来的.传统的SQL数据库(关系型数据库)都具有ACID属性,对一致性要求很高,因此降低了A(availability)和P(partition tolerance).为了提高系统性能和可扩展性,必须牺牲C(consistency).
- Consistency(一致性), 数据一致更新,所有数据变动都是同步的
- Availability(可用性), 好的响应性能
- Partition tolerance(分区容错性) 可靠性
依据CAP理论,从应用的需求不同,数据库的选择可从三方面考虑:
- 考虑CA,这就是传统上的关系型数据库(RDBMS).
- 考虑CP,主要是一些Key-Value数据库,典型代表为Google的Big Table,将各列数据进行排序存储.数据值按范围分布在多台机器,数据更新操作有严格的一致性保证.
- 考虑AP,主要是一些面向文档的适用于分布式系统的数据库,如Amazon的Dynamo,Dynamo将数据按key进行Hash存储.其数据分片模型有比较强的容灾性,因此它实现的是相对松散的弱一致性——最终一致性.
- Status
- aborted
- insession
- won
- lost
如何探测客户端掉线? 掉线之后GameHistory如何存?
如果浏览器支持HTML5,用websocket; 不支持就用ajax.
For websocket, cpp websocket server with seasocks:
void Thread_API_WS(Server* p) {
const string DOC_ROOT = "~/.sentosa/";
shared_ptr<wshandler> handler(new wshandler(p));
handler->initcallbacks();
p->addWebSocketHandler("/ws", handler);
p->serve(expand_user(DOC_ROOT).c_str(), stoi(CR(WS_MON_PORT)));
}
...
void wshandler::onDisconnect(WebSocket* p) {
// 标记game status为aborted.
TTPrint("Disconnected:%s,%s\n", p->getRequestUri().c_str(),
formatAddress(p->getRemoteAddress()).c_str());
}Client side javascript:
<script>
var ws = new WebSocket('ws://research.quant365.com:8888/ws');
var $message = $('#message');
ws.onopen = function(){
$message.attr("class", 'label label-success');
};
ws.onmessage = function(ev){
var json = JSON.parse(ev.data);
if (json.msg == "hello"){
ws.send("AddMeToObserverLOG");
}else{
if (json.hasOwnProperty('msg')){
$message.val($message.val()+json.msg);
}else{
$message.val($message.val()+ev.data+"\n");
}
}
};
ws.onclose = function(ev){
$message.text('closed');
};
ws.onerror = function(ev){
$message.text('error occurred');
};
</script>Peak Concurrent Users (online gaming) http://www.acronymfinder.com/Peak-Concurrent-Users-(online-gaming)-(PCU).html
Redis + HDFS:
HBase可以替代redis吗? https://www.zhihu.com/question/35912020
100M rows, 1k per 10 rows, then 10M*1k = 10G new data per day.
5M DAU, 86K seconds per day, 500 concurrent users per seconds, and PCU 500x20=10K.
C1M-Servers: https://github.com/smallnest/C1000K-Servers
使用四种框架分别实现百万websocket常连接的服务器
http://colobu.com/2015/05/22/implement-C1000K-servers-by-spray-netty-undertow-and-node-js/
在一台系统上,连接到一个远程服务时的本地端口是有限的.根据TCP/IP协议,由于端口是16位整数,也就只能是0到 65535,而0到1023是预留端口,所以能分配的端口只是1024到65534,也就是64511个.也就是说,一台机器一个IP只能创建60K多个长连接. 要想达到更多的客户端连接,可以用更多的机器或者网卡,也可以使用虚拟IP来实现,比如下面的命令增加了19个IP地址,其中一个给服务器用,其它18个给client,这样可以产生18 * 60000 = 1080000个连接.
Redis Cluster
Redis Cluster is the preferred way to get automatic sharding and high availability.
https://redis.io/topics/partitioning
Redis Cluster does not use consistent hashing, but a different form of sharding where every key is conceptually part of what we call an hash slot. There are 16384 hash slots in Redis Cluster, and to compute what is the hash slot of a given key, we simply take the CRC16 of the key modulo 16384.
Redis Cluster is not able to guarantee strong consistency.
https://redis.io/topics/cluster-tutorial
我开始想用memcached+mysql的解决方案.现在发现redis+hbase,应该可以秒杀上面那个.
MongoDB:
https://github.com/jussi-s/hangman
https://github.com/holyspecter/node_hangman
https://github.com/edoardo849/vino
Redis: