Chapter 64 Other Companies






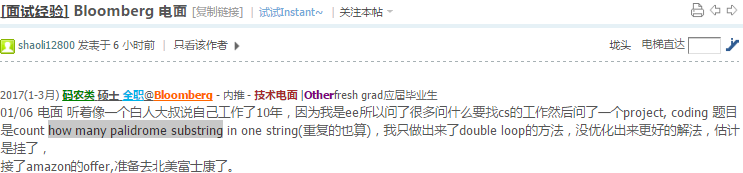
64.1 Count All Palindrome Substrings in a String
http://www.geeksforgeeks.org/count-palindrome-sub-strings-string/
64.2 Josephus problem

http://www.1point3acres.com/bbs/thread-218908-1-1.html
https://en.wikipedia.org/wiki/Josephus_problem
https://zh.wikipedia.org/wiki/%E7%BA%A6%E7%91%9F%E5%A4%AB%E6%96%AF%E9%97%AE%E9%A2%98
http://blog.csdn.net/wuzhekai1985/article/details/6628491
http://brokendreams.iteye.com/blog/2227334

http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=218980
64.3 390. Elimination Game
There is a list of sorted integers from 1 to n. Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
Repeat the previous step again, but this time from right to left, remove the right most number and every other number from the remaining numbers.
We keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Find the last number that remains starting with a list of length n.
Example:
Input:
n = 9,
1 2 3 4 5 6 7 8 9
2 4 6 8
2 6
6Output: 6
64.4 116. Populating Next Right Pointers in Each Node
 https://leetcode.com/problems/populating-next-right-pointers-in-each-node/
https://leetcode.com/problems/populating-next-right-pointers-in-each-node/
perfect binary tree (ie, all leaves are at the same level, and every parent has two children)
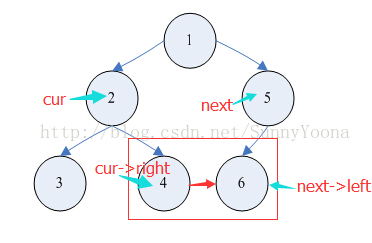
Algo 1 - recursive:
这道题解法还是挺直白的,如果当前节点有左孩子,那么左孩子的next就指向右孩子.如果当前节点有右孩子,那么判断,如果当前节点的next是null,说明当前节点已经到了最右边,那么右孩子也是最右边的,所以右孩子指向null.如果当前节点的next不是null,那么当前节点的右孩子的next就需要指向当前节点next的左孩子.递归求解就好.
class Solution {
public:
void connect(TreeLinkNode *root) {
if(!root){ return; }
if(root->left) root->left->next = root->right;
if(root->right){
if(root->next) root->right->next = root->next->left;
else root->right->next=0;
}
connect(root->left);
connect(root->right);
}
};Algo 2 - BFS:
class Solution {
public:
void connect(TreeLinkNode *root) {
if (!root) return;
queue<TreeLinkNode*> q;
q.push(root);
while (!q.empty()) {
int size = q.size();
for (int i = 0; i < size; ++i) {
TreeLinkNode *t = q.front(); q.pop();
if (i < size - 1) {
t->next = q.front();
}
if (t->left) q.push(t->left);
if (t->right) q.push(t->right);
}
}
}
};Algo 3:
上面2种方法虽然叼,但是都不符合题意,题目中要求用O(1)的空间复杂度,所以我们来看下面这种碉堡了的方法.用两个指针start和cur,其中start标记每一层的起始节点,cur用来遍历该层的节点
64.5 117. Populating Next Right Pointers in Each Node II
https://leetcode.com/problems/populating-next-right-pointers-in-each-node-ii/
参考: http://www.cnblogs.com/grandyang/p/4290148.html
Algo 1 - recursive:
struct Solution {
void connect(TreeLinkNode *root) {
if (!root) return;
TreeLinkNode *p = root->next;
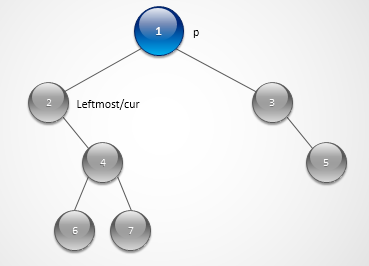
while (p) { // while很关键,见上图最底层
if (p->left) { p = p->left; break; }
if (p->right) { p = p->right; break; }
p = p->next;
}
if (root->right) root->right->next = p;
if (root->left) root->left->next = root->right ? root->right : p;
connect(root->right);
connect(root->left);
}
};Algo 2 - BFS:
可以完全照搬116的BFS方法
Algo 3:
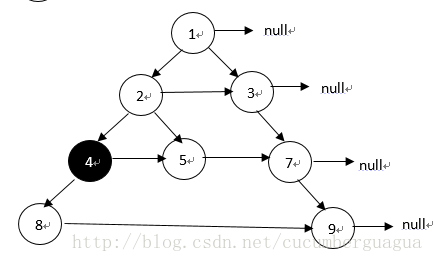
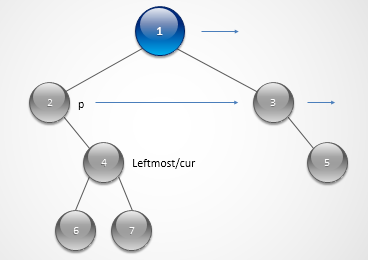
下面贴上constant space的解法,这个解法乍看上去蛮复杂,但是仔细分析分析也就那么回事了,首先定义了一个leftMost的变量,用来指向每一层最左边的一个节点,由于左子结点可能缺失,所以这个最左边的节点有可能是上一层某个节点的右子结点,我们每往下推一层时,还要有个指针指向上一层的父节点,因为由于右子节点的可能缺失,所以上一层的父节点必须向右移,直到移到有子节点的父节点为止,然后把next指针连上,然后当前层的指针cur继续向右偏移,直到连完当前层所有的子节点,再向下一层推进,以此类推可以连上所有的next指针.
struct Solution {
void connect(TreeLinkNode *root) {
if (!root) return;
TreeLinkNode *leftMost = root;
while (leftMost) {
TreeLinkNode *p = leftMost;
//要找下一层的leftMost,p must not be a leaft node!!
while (p && !p->left && !p->right) //如果p是leaf node
p = p->next; // find non-leaf node
if (!p) return; // if cannot find non-leaf node, we are done!!
TreeLinkNode *cur = leftMost = p->left ? p->left : p->right;
while (p) {
if (cur == p->left) {
if (p->right) {
cur->next = p->right;
cur = cur->next;
}
p = p->next;
} else if (cur == p->right) {
p = p->next;
} else {
if (!p->left && !p->right) {
p = p->next;
continue;
}
cur->next = p->left ? p->left : p->right;
cur = cur->next;
}
}
}
}
};两个while loop,一个负责层层往下移动,一个负责同一层,从左到右移动.
64.6 387. First Unique Character in a String
https://leetcode.com/problems/first-unique-character-in-a-string/
这道题确实没有什么难度,我们只要用哈希表建立每个字符和其出现次数的映射,然后按顺序遍历字符串,找到第一个出现次数为1的字符,返回其位置即可
64.7 64. Minimum Path Sum
https://leetcode.com/problems/minimum-path-sum
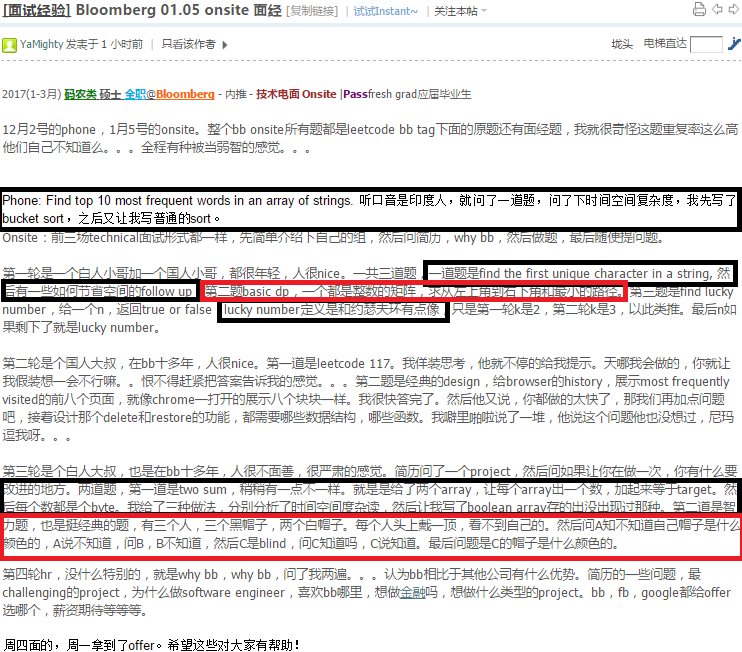
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=218970
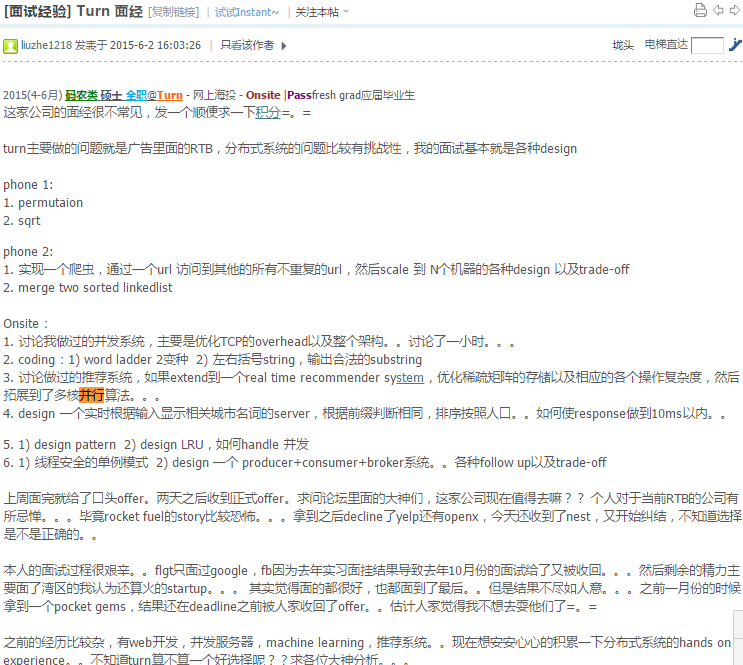
http://www.1point3acres.com/bbs/thread-135677-1-1.html
https://www.turn.com/company/careers/software-engineer-distributed-systems
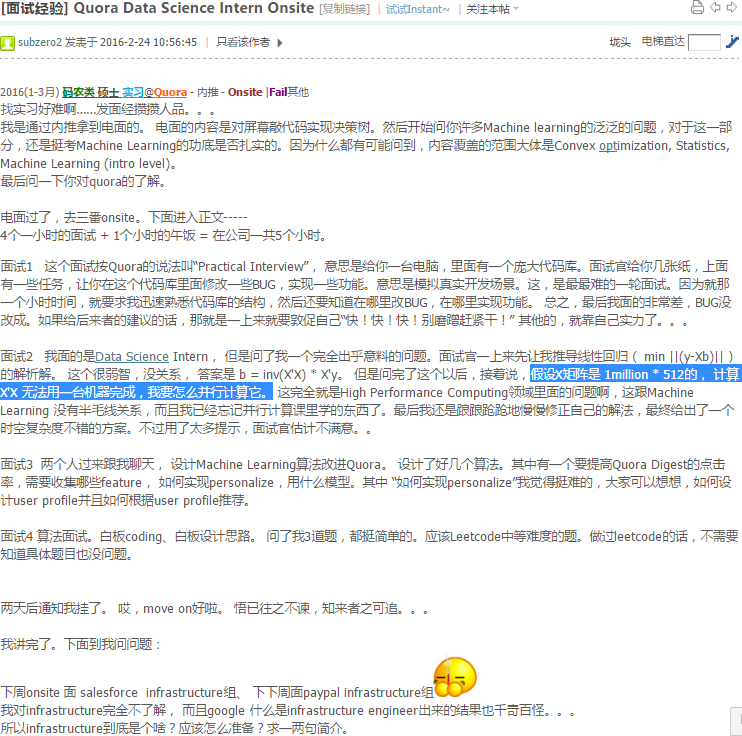
并行计算:
https://en.wikipedia.org/wiki/Bitonic_sorter
用 C++ 实现大整数的加减,思路是什么?
https://www.zhihu.com/question/24958327
并行的超前进位加法器
https://en.wikipedia.org/wiki/Carry-lookahead_adder
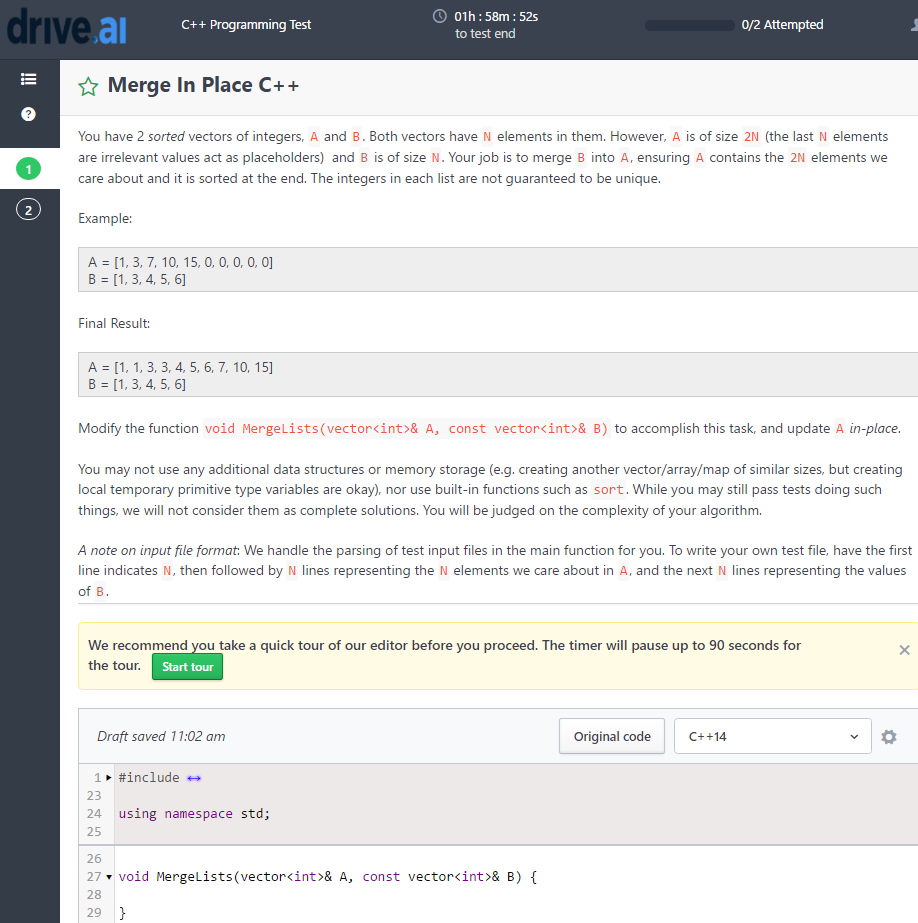
64.9 Drive.AI Sort Build Dependency
shared_ptr<vector<string>> serialize_build_order(const vector<pair<string, string>>& relations) {
shared_ptr<vector<string>> r(new vector<string>);
map<string,set<string>> suc, pre;
set<string> ns;
for(auto& p: relations) suc[p.second].insert(p.first), pre[p.first].insert(p.second), ns.insert(p.second);
for(auto& p: pre) ns.erase(p.first);
while(!ns.empty()){
set<string> tmp;
for(auto i: ns)
if(suc.count(i)){
for(auto j: suc[i]){
if(pre.count(j)==0) continue;
pre[j].erase(i);
if(pre[j].empty()) pre.erase(j), r->push_back(j), tmp.insert(j);
}
suc.erase(i);
}
ns=tmp;
}
return r;
}64.10 Multithread Token Bucket + Crawler
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=277537
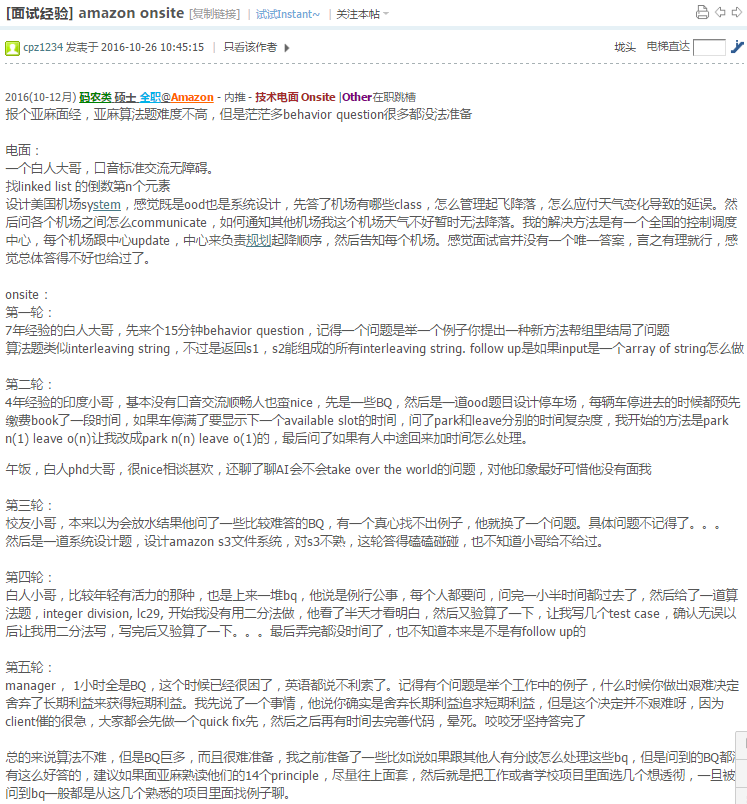
2017(1-3月) 码农类 硕士 全职Dropbox - 猎头 - Onsite |Fail在职跳槽 1. 多线程tokenbucket, 实现gettoken(int n), token不够就block. 我用的pthread_cond_timedwait, 但是要注意sleep 的时间不保证是准确的, 所以需要while loop sleep . 2. 多线程爬虫带终止条件,秒了, 附代码(crtl+A显示代码), 另外要估算线程数量(based on IO_TIME/CPU_TIME)
pthread_mutex_t lock;
pthread_cond_t cond;
queue<string> seeds;
unordered_set<string> visited;
int nwait = 0;
int nthreads = N;
crawl() {
while(1) {
pthread_mutex_lock(&lock);
while(seeds.empty()){
nwait++:
if(nwait==N) {
pthread_cond_signal(&cond);
pthread_mutex_unlock(&lock);
return;
}. from: 1point3acres.com/bbs
pthread_cond_wait(&cond, &lock);
nwait—;
}
string url = seeds.front();. From 1point 3acres bbs
seeds.pop();. 1point3acres.com/bbs
pthread_mutex_unlock(&lock);. visit 1point3acres.com for more.
vector<string> urls = geturls(url);
pthread_mutex_lock(&lock);
for(auto &a:urls) {
if(visited.count(a)) continue;
visited.insert(a);-google 1point3acres
seeds.push(a);
}
if(!seeds.empty()) pthread_cond_broadcast(&cond);
pthread_mutex_unlock(&lock);
}
}
- behaviour, failed project etc
- dive deep
- 设计twitter, 从single box 扩展.post_tweet, read_tweet, get_news_feed. 怎么实现scroll up/down 更新feed(存上次更新的timestamp) 祝大家好运.另求bless余下的面试有好结果
64.11 517. Super Washing Machines
https://leetcode.com/problems/super-washing-machines/
http://www.cnblogs.com/grandyang/p/6648557.html
我们就用上面那个例子,有四个洗衣机,装的衣服数为[0, 0, 11, 5],最终的状态会变为[4, 4, 4, 4],那么我们将二者做差,得到[-4, -4, 7, 1],这里负数表示当前洗衣机还需要的衣服数,正数表示当前洗衣机多余的衣服数.我们要做的是要将这个差值数组每一项都变为0,对于第一个洗衣机来说,需要四件衣服可以从第二个洗衣机获得,那么就可以把-4移给二号洗衣机,那么差值数组变为[0, -8, 7, 1],此时二号洗衣机需要八件衣服,那么至少需要移动8次.然后二号洗衣机把这八件衣服从三号洗衣机处获得,那么差值数组变为[0, 0, -1, 1],此时三号洗衣机还缺1件,就从四号洗衣机处获得,此时差值数组成功变为了[0, 0, 0, 0],成功.那么移动的最大次数就是差值数组中出现的绝对值最大的数字,8次
class Solution {
public:
int findMinMoves(vector<int>& machines) {
int sum=accumulate(machines.begin(), machines.end(), 0), avg=sum/machines.size();
if (sum%machines.size()!=0) return -1;
for(int i=0;i<machines.size();++i) machines[i]-=avg;
int ma=INT_MIN, cur=0;
for(int i: machines)
cur+=i, ma=max(max(abs(cur),i), ma);
return ma;
}
};注意
machines[i]-=avg;
换成
machines[i]=machines[i]-avg;
也是一样的.
错误:
1. ma=max(max(abs(cur),abs(i)), ma);
m=[9,1,8,8,9]
avg = 35/5 = 7
m[1] need 6 dresses, but it doesn’t mean we need 6 rounds move, because it can get two dresses in one round of move from its neighbours m[0] and m[2].
64.12 Graph Valid N-ary Tree
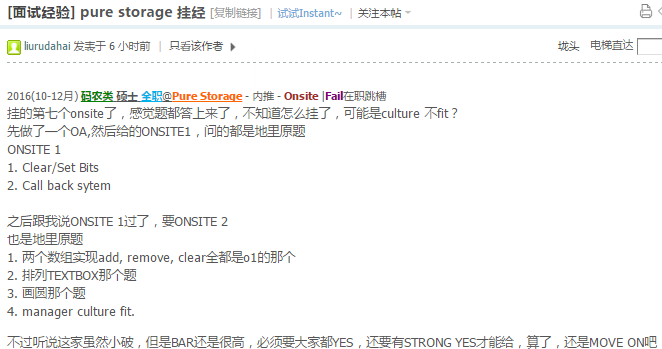
2017(7-9月) 码农类 硕士 全职Amazon - 猎头 - Onsite |Fail在职跳槽
5月底做完OA得到了onsite机会,一共四轮, OA是base ball和根据array建立BST,onsite完了后一周内收到拒信:
每轮都是先15分钟左右的BQ,然后就是算法设计啥的:
1. Hiring Manager, 算法题,numbers of island小变种,求所有岛屿的最大值,依然是DFS增加一个全局的max值标识即可;
2. Other team member,系统设计,设计chat system,其中问到太大并发和局部异常如何处理,如何能够精确找到对方,聊的过
程中忘了分析在线和不在线的情况怎么处理了;
3. Other team member,OOD,餐馆预定座位,设计了customer,restaurant, table类,在面试官提示下补上了
reservation类(最关键的类没第一时间说出),用的command pattern;
4. Team member, 算法题, 判断一个graph是否是n-ary tree,这道题没见过,和面试官讨论了一下思路也没理清,一开始把
所有grpah的点和其关联点用hashmap存了,然后遍历出每个点去判断是否有环,dfs去判断是否n-ary tree,后来照着自己写的
东西给面试官讲的时候就发现走不通,应该先找到root点,然后判断,而且图的表示法应该用adjacent table,这轮应该是失
败的.http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=283650
http://www.1point3acres.com/bbs/forum.php?mod=redirect&goto=findpost&ptid=283650&pid=3077723&fromuid=91137
Refer to: Graph Valid Tree
Connected, acyclic, E=V-1.
64.13 Maximize number of 0s by flipping a subarray
Wish (做电子商务)最近招人蛮多的,想去三番的同学可以试一下.感觉公司前景还不错.
先说电面, 直接做题,题目是给一些关系,比如 A 和 B的关系, B和 C的关系… 然后给一个 start 和target, print 出所有可以从start 出发,在target截止,并且带上 relationship. 比如 A brother B, B mother C, B mother A, B friend D. 给 start = A, target = C 的话, 要print 出 A brother B, B mother C. 用dfs就可以了,没什么特别tricky的
Onsite:
第一轮: 设计一个21点的赌博游戏. 游戏里有1个庄家,k个玩家,玩法是 每个玩家刚开始有2张牌,面朝上,庄家2张牌,一张面朝上. 从第一个玩家开始发牌,可以选择hit/pass. 如果hit的话就加分,但如果超过21点就输(可以选择很多次,如果玩家和庄家都没有超过21点, 比谁的分大. 最后print 出每个玩家赢还是庄家赢.主要考点是OOD,具体怎么实现不是特别care, 比如洗牌什么的只问了用什么data structure 好之类的.
第二轮:第一题,给出2个数组,比如A =[1,6,9], B = [1,1,1]. 每个数字相加,但是保证每个slot 的值小于10, 如果大于10 就要分开.比如刚才2个A, B 的结果应该输出 [2,7,1,0];
第二题, 交通控制.给出一个Char Array, 里面只有 R, G. 现在要选择一个范围,使得 R 变成G,G变成R,并使得G的个数- R的个数最大.输出这个范围并且输出最大结果
第三轮:第一题,给出一个10K的文档,里面很多文章.现在给出一个String query, 找到最有关系的10个文章.第二题是加油站问题,给出Gas, Cost 2组数组.输出所有可以开头并且走完一圈的index.
第四轮: 这轮就简单一点了,应该是一个老大的人,问了下简历和project. 题目是给出一个sorted A, 和Sorted B, 并且B的长度是A的两倍,B组数列后半个组是空的.要求把这2个merge起来,sorted,并且不要extra space..
整体感觉面的还不错但OOD那轮感觉一般,不知道设计的符不符合他的期望.其他的题目倒是都弄出来了..发个面经,希望可以帮助到大家.(PS,面试官说他们急缺人,大家可以投下试试)
http://bit.ly/2xwNkXq
http://www.geeksforgeeks.org/maximize-number-0s-flipping-subarray/
Solved by: Kadane Algo
Similar Problem: flip-zeroes
Given a binary array, find the maximum number zeros in an array with one flip of a subarray allowed. A flip operation switches all 0s to 1s and 1s to 0s.
Examples:
Input : arr[] = {0, 1, 0, 0, 1, 1, 0}
Output : 6
We can get 6 zeros by flipping the subarray {1, 1}This problem can be reduced to largest subarray sum problem. The idea is to consider every 0 as -1 and every 1 as 1, find the sum of largest subarray sum in this modified array. This sum is our required max_diff ( count of 0s – count of 1s in any subarray). Finally we return the max_diff plus count of zeros in original array.
// A Kadane's algorithm based solution to find maximum
// number of 0s by flipping a subarray.
int findMaxZeroCount(bool arr[], int n){
// Initialize count of zeros and maximum difference
// between count of 1s and 0s in a subarray
int orig_zero_count = 0;
// Initiale overall max diff for any subarray
int max_diff = 0;
// Initialize current diff
int curr_max = 0;
for (int i=0; i<n; i++) {
// Count of zeros in original array (Not related
// to Kadane's algorithm)
if (arr[i] == 0)
orig_zero_count++;
// Value to be considered for finding maximum sum
int val = (arr[i] == 1)? 1 : -1;
// Update current max and max_diff
curr_max = max(val, curr_max + val);
max_diff = max(max_diff, curr_max);
}
max_diff = max(0, max_diff);
return orig_zero_count + max_diff;
}We want most G. So we can make G=-1, and R=1.
64.14 134. Gas Station
There are N gas stations along a circular route, where the amount of gas at station i is gas[i].
You have a car with an unlimited gas tank and it costs cost[i] of gas to travel from station i to its next station (i+1). You begin the journey with an empty tank at one of the gas stations.
Return the starting gas station’s index if you can travel around the circuit once, otherwise return -1.
Note: The solution is guaranteed to be unique.
https://leetcode.com/problems/gas-station/
这道转圈加油问题不算很难,只要想通其中的原理就很简单. 我们首先要知道能走完整个环的前提是gas的总量要大于cost的总量,这样才会有起点的存在. Also, if the total number of gas is bigger than the total number of cost. There must be a solution. 假设开始设置起点start = 0, 并从这里出发,如果当前的gas值大于cost值,就可以继续前进,此时到下一个站点,剩余的gas加上当前的gas再减去cost,看是否大于0,若大于0,则继续前进. 当到达某一站点时,若这个值小于0了,则说明从起点到这个点(inclusive)的任何一个点都不能作为起点,则把起点设为下一个点,继续遍历. 当遍历完整个环时,当前保存的起点即为所求. 代码如下:
T: \(O(N)\), 采用STL:
struct Solution {
int canCompleteCircuit(vector<int> &gas, vector<int> &cost) {
transform(gas.begin(), gas.end(), cost.begin(), gas.begin(), minus<int>());
partial_sum(gas.begin(), gas.end(), gas.begin()); // cum sum
if(gas.back()<0) return -1; // total gas less than cost
return distance(gas.begin(),next(min_element(gas.begin(), gas.end())))%gas.size();
}
};第三行transform的作用类似:
for(int i=0;i<gas.size();++i) gas[i]-=cost[i];同样的算法,如果手写循环代码是这样的:
struct Solution {
int canCompleteCircuit(vector<int> &gas, vector<int> &cost) {
int total = 0, sum = 0, start = 0;
for (int i = 0; i < gas.size(); ++i) {
total += gas[i] - cost[i], sum += gas[i] - cost[i];
if (sum < 0)
start = i + 1, sum = 0;
}
return (total<0)?-1:start;
}
};注意这里不需要判断start是否会pass the end,因为假设start pass the end, then i will be the last index of the vector and the sum is less than 0, which means all points including the last one cannot be the starting point, so total should be negative.
这个题如果去掉cost,还有简化版本的: http://bit.ly/2xxEiJy
Some discussion: http://bit.ly/2xyd7OP
How to do a cirular scan in an array?
while(1){
j++, i=j%L;
v[i]...
}64.15 Design BlackJack
https://my.oschina.net/zjzhai/blog/203842
Wish onsite第一轮:easy string 题目 + 红绿灯
第二轮: project dive + return a probability key from a given map, e.g. map<String, Integer> contains Apple 10, Orange 20, then ghe method 三分之一的概率返回苹果,三分之二返回橘子
第三轮:给一个文件里有userid + timestamp, 具体请翻以前的面镜.
第四轮: project dive
总体感觉公司一般,虽然这个startup已经估值3个B,但是个人感觉还是泡沫大了些.公司就是一群小年轻Asian American,比较unexperienced for handling complicated systems, 这些人也没有明显的显示出super smart or strong background like graduated from MIT or bla.
值得一题的是,公司不给报销车费,从机场到三番酒店的费用,也没有报销任何lunch, dinner or other fees. 只提供机票和很一般的酒店(酒单还特意在邮件中问道你是否需要酒店).公司是provide lunch 和dinner给employee的,但是我的interview 是从1 点开始,故意错开了吃饭时间,并且还在邮件中提到公司周边有不错的restaurant, 可以自己去那吃.
总体感觉除非是well established unicron like uber airbnb, pinterest or bla, 一般的在crunchtech上的公司还是他妈不太靠谱.风险与机遇共存吧.
http://bit.ly/2j1l383
64.16 Merge Sort
https://en.wikipedia.org/wiki/Merge_sort
No matter iterative or recursive methods, this sub function is needed:
// merge the two haves v[l..m] and v[m+1..r] of vector v
void sub_merge(vector<int>& v, int l, int m, int r){
int L=m-l+1;
vector<int> t(L);
for(int i=0; i<L; ++i)
t[i] = v[l+i];
int i=0, j=m+1;
while(i<L && j<=r)
if(v[j]<t[i]) v[l++]=v[j++]; else v[l++]=t[i++];
while(i<L) // dont forget this
v[l++]=t[i++];
}64.16.2 Iterative
http://www.geeksforgeeks.org/iterative-merge-sort/
Unlike Iterative QuickSort, the iterative MergeSort doesn’t require explicit auxiliary stack.
void mergeSort_iterative(vector<int>& v){
int L=v.size();
for(int len=1; len<L; len<<=1){ // understand len<L
for(int hd=0; hd<L; hd+=2*len){
int mi=hd+len-1, tl=min(mi+len, L-1);
sub_merge(v, hd, mi, tl);
}
}
}Check Merge Sorted Array
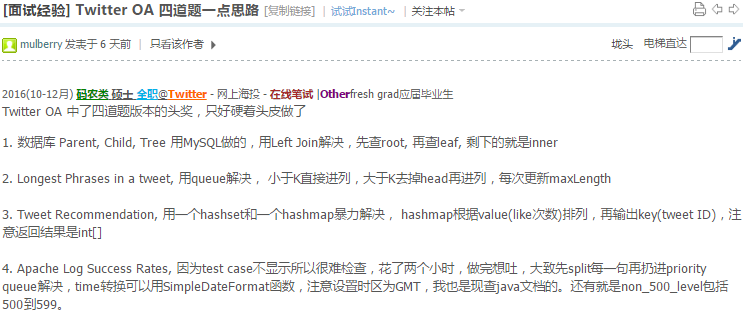
2017(7-9月) 码农类 硕士 全职 Wish - 网上海投 - 技术电面 Onsite |Pass在职跳槽 店面:2sum/3sum/ksum
面的产品组
昂赛:(最近面了很多家 有点记不全了 一轮大概平均两题)
coding部分: 1)implement merge索特 (recursive+iterative)
2)合并两个索特好的数组 一个数组长度是m+n 另一个数组长度是n 合并两个数组存在长的数组里
3)给一个数字 打印对应的钻石 问了时间复杂度
比如1 就是 1
3 是 1
121
1
5 是 1
121
12321
121
1 4)之前面经也有 n个人比赛 可以并列第一 问有多少种结果
Design:假设Bot的定义是一个ip在过去N秒中访问网站(不一定是一个网页 可以是不同的API)总计超过M次, 怎样设计一个可以探测bot的layer并且应该放在系统的哪个部分
包中饭 不知道中饭轮有没有feedback
http://bit.ly/2j1Ky9c
64.17 Print Diamond
void printDiamond(int n){
int i=1, h=n;
for(int i=0;i<n;++i) {
int left=abs(h/2-i), mid=n-2*left, right=left;
while(left--) cout << "_";
while(mid--) cout << "X";
while(right--) cout << "_";
cout << endl;
}
}If you want to input digits like above, the code is:
void printDiamond(int n){
int i=1, h=n;
for(int i=0;i<n;++i) {
int left=abs(h/2-i), mid=n-2*left, right=left;
while(left--) cout << "_";
for(int i=0;i<mid; ++i)
if(i<=mid/2) cout<<i+1; else cout<< mid-i;
while(right--) cout << "_";
cout << endl;
}
}2017(4-6月) 码农类 硕士 全职 Wish - 网上海投 - Onsite |Passfresh grad应届毕业生
电面
1. 给一个数, 如何判断是不是斐波那契数
2. Given a ODD number, print the diamond with *.
like, input 3
// _X_
// XXX
// _X_ input 5
// X
// XXX
// XXXXX
// XXX
// X 要求最好是递归,但是迭代也可以
On site
第1轮: mergetwo sorted arrays, merge n sorted DataStream, 最后一题,就是有n个人, 比赛, 问你有多少种比赛结果排名,每个人可以独自一人一组, 也可以和其他人组成团体, 比如n= 2, 两个人A,B, 可能的结果有3种
A 第一,B 第二
B 第一,A 第二
A, B 团体第一
第2轮: threesum, k sum, number of island
第3轮: top klargest from an array, sort, heap, quick select 三种方法都让写一遍, 然后让证明quick select的平均复杂度是O(n)的
第4轮:
A bot is an id that visit the site m times in the last nseconds, given a list of logs with id and time sorted by time, returnall the bots’s id
这家很抠门,on site旅途中吃饭不报销 http://bit.ly/2j1ii6M
64.18 N People Tournament
N People; one group can be formed by one or more than one persons. No any two groups have the same rank. How many different possible ranks in total?
- DP:
dp[i][j] = dp[i-1][j]*j + dp[i-1][j-1]*j = (dp[i-1][j]+dp[i-1][j-1])*jwhere i people and j groups
64.19 Fibonacci Number
https://en.wikipedia.org/wiki/Fibonacci_number
64.19.2 Algo 2: Power of Matrix 1110 - O(LogN)
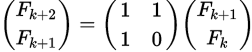
- Recursion
vector<vector<long long>> multiply(const vector<vector<long long>>& l,
const vector<vector<long long>>& r) {
vector<vector<long long>> res(2,vector<long long>(2));
for(int i=0;i<2;++i)
for(int j=0;j<2;++j)
for(int k=0;k<2;++k)
res[i][k]+=l[i][j]*r[j][k];
return res;
}
vector<vector<long long>> matrix_power(int n){
vector<vector<long long>> l={{1,1},{1,0}};
if(n==1){return l;}
else if(n==2){
return multiply(l, l);
}else{
auto res=matrix_power(n/2);
if(n&1) {
auto t = multiply(res, res);
return multiply(t, l);
}else
return multiply(res, res);
}
}
long long fib_BigOLogN(int n){
if(n<3) return 1;
auto m=matrix_power(n-2);
return m[0][0]+m[0][1];
}- Iteration
vector<vector<long long>> multiply(const vector<vector<long long>>& l, const vector<vector<long long>>& r) {
vector<vector<long long>> res(2,vector<long long>(2));
for(int i=0;i<2;++i)
for(int j=0;j<2;++j)
for(int k=0;k<2;++k)
res[i][k]+=l[i][j]*r[j][k];
return res;
}
long long fib_BigOLogN(int n){
if(n<3) return 1;
vector<vector<long long>> r={{1,0}, {0,1}}; //identity matrix
vector<vector<long long>> t={{1,1}, {1,0}}; // seed
n-=2;
while(n){
if(n&1) r=multiply(r, t);
t=multiply(t,t);
n>>=1;
}
return r[0][0]+r[0][1];
}64.21 Unrolled Linked List
2017(10-12月) 码农类 硕士 全职 Indeed - 校园招聘会 - Onsite |Failfresh grad应届毕业生 三轮白板都是面经题 1.moving average 有follow up问如何很快的给出median,可以用linkedlist或者2 heaps维护,这样加入的时候会复杂很多但是维护和输出median很方便
2.Trie
3.unrolled linked list有follow up问如何更快,没答出来,说是用rope可以,不是很了解
第一题没说出heap,最后一题不知道rope,其他感觉答得还行.但是最后收到了拒信.
http://www.1point3acres.com/bbs/thread-300718-1-1.html
Like array and linked list, unrolled Linked List is also a linear data structure and is a variant of linked list. Unlike simple linked list, it stores multiple elements at each node. That is, instead of storing single element at a node, unrolled linked lists store an array of elements at a node. Unrolled linked list covers advantages of both array and linked list as it reduces the memory overhead in comparison to simple linked lists by storing multiple elements at each node and it also has the advantage of fast insertion and deletion as that of a linked list.
Unrolled Linked List
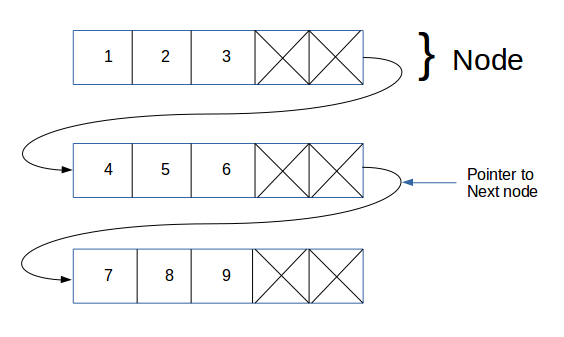
Advantages:
Because of the Cache behavior, linear search is much faster in unrolled linked lists.
In comparison to ordinary linked list, it requires less storage space for pointers/references.
It performs operations like insertion, deletion and traversal more quickly than ordinary linked lists (because search is faster).Disadvantages:
The overhead per node is comparatively high than singly linked lists. Refer an example node in below code.public class UnrolledLinkedList {
UnRolledList list;
public UnrolledLinkedList(){
list = new UnRolledList(new Node(),100);
}
public char get(int index){
Node node = list.head;
int total = list.totalLen;
if(node == null || total < 0 || index > total){
return ' ';
}
while(node!=null && node.len < index){
index -= node.len;
node = node.next;
}
if(node == null){
return ' ';
}
return node.chars[index];
}
public void insert(char ch, int index){
Node node = list.head;
int total = list.totalLen;
if(node == null || total < 0 || index > total){
return ;
}
while(node!=null && node.len < index){
index -= node.len;
node = node.next;
}
if(node == null){
return;
}
if(node.len < 5) {
for(int i = node.len; i>index; i--){
node.chars[i] = node.chars[i-1];
}
node.chars[index] = ch;
} else {
Node newNode = new Node();
newNode.len = 5-index;
for(int i = index; i<node.len; i++){
newNode.chars[i-index] = node.chars[i];
node.chars[i] =' ';
}
node.chars[index] = ch;
node.len= index;
newNode.next = node.next;
node.next = newNode;
}
}
public static void main(String[] args) {
}
class Node {
char[] chars = new char[5];
int len;
Node next;
public Node (){
}
}
class UnRolledList {
Node head;
int totalLen;
public UnRolledList(Node head, int total){
this.head= head;
this.totalLen= total;
}
}
}一天16人,我们8个人上午whiteboard,下午online coding.我是上午whiteboard,下午coding.
第一轮:给一颗binary tree,有以下数据结构
class Edge {
Node node;
int cost; //大于等于0
}
class Node {
List<Edge> edges;
}
找从root到叶节点cost之和最小的路径,返回该leaf node.(dfs)
follow-up:如果不是binary tree的结构,而是任意的单向图,问代码还是否work(yes)
有没有优化的地方?(我用hashmap存下每个节点到叶节点的distance,这样再次访问到该叶节点就不必dfs下去).时间复杂度?(优化后是O(V+E))
第二轮:Unrolled Linked List,有以下数据结构:
class Node {
char[] chars = new char[5]; //固定大小5
int len;
}
class LinkedList {
Node head;
int totalLen;
}
实现以下成员函数:char get(int index), void insert(char ch, int index)
get比较容易,就是从head traverse,定位第index个char;insert有点麻烦,有几种情况需要考虑.
时间有点不太够,所以insert函数没完全实现 T.T
第三轮:get K apearances numbers in N sorted streams.
这道没什么说的,和其他面经出入不大,我直接给出用min heap的solution,他问了下时间复杂度,然后说这就是想要的最好solution,没什么问的了.
中午吃饭,食堂超赞!吃的东西种类也很多!
下午online coding,也是面经题,用STDIN和STDOUT,输入如下:
N
...
... --> document,有N行string,每一个string是space delimited
...
M
...
A
B & C --> M行query
D | E
...
要求输出如下:对每一个query,依次print document中满足query条件的行号,其中行号根据key word出现频率排序,对于频率一样的,小的行号优先.
其中出现的频率按照如下定义:如果string中单词A cnt1次,单词B cnt2次,则A&B和A | B的频率都按照cnt1 + cnt2计算.
后面还有几道文字题目:分析时间和空间复杂度;如果给你一天时间完成,你还有什么优化,如果有很多很多记录,很多很多user querys,有什么优化.http://www.1point3acres.com/bbs/thread-182369-1-1.html
Given a LinkedList, every node contains a array. Every element of the array is char implement two functions 1. get(int index) find the char at the index 2. insert(char ch, int index) insert the char to the index
class Node{
char[] chars = new char[5]; //定长5,反正总要有定长.
int len; //表示数组里面实际有几个字母
Node next;
public Node(){}
}
class LinkedList{
Node head;
int totalLen; //这个totalLen代表所有char的个数
public LinkedList(Node head, int total){
this.head = head;
this.totalLen = total;
//可能totalLen是不给的,要遍历一遍去求.
int count = 0;
Node cur = head;
while (cur != null) {
count += cur.len;
cur = cur.next;
}
totalLen = count;
}
public char get(int index){
if (index < 0 || index >= totalLen || totalLen == 0) {
return ' ';
}
Node cur = head;
while(cur != null && index >= 0){
if (index >= cur.len) {
index -= cur.len;
}
else {
return cur.chars[index];
}
//总忘了往后爬一步cur
cur = cur.next;
}
return ' ';
}
//insert需要考虑1.普通插进去.2.插入的node满了,要在后面加个node.
//3.插入的node是空的,那就要在尾巴上加个新node.
//还需要考虑每个node的len,以及totalLen的长度变化.
public void insert(char ch, int index){
if (index > totalLen) {
return;
}
Node cur = head;
while(cur != null && index >= 0){
if (index >= cur.len) {
index -= cur.len;
}
else {
if (cur.len == 5) {
Node newNode = new Node();
newNode.chars[0] = cur.chars[4];
newNode.len = 1;
newNode.next = cur.next;
cur.next = newNode;
cur.len -= 1;
}
cur.len += 1;
for(int i = cur.len-1; i > index; i--){
cur.chars[i] = cur.chars[i-1];
}
cur.chars[i] = ch;
break;
}
cur = cur.next;
}
if (cur == null) {
Node newNode = new Node();
newNode.chars[0] = ch;
newNode.len = 1;
Node tail = new Node();
tail.next = head;
while(tail.next != null){
tail = tail.next;
}
tail.next = newNode;
}
totalLen += 1;
}
}
//链表题到时候画一个下面的小case,就能对准index了.
public static void main(String[] args) {
Node n1 = new Node(); //a b
Node n2 = new Node(); //b
Node n3 = new Node(); //a b c d e
n1.chars[0] = 'a';
n1.chars[1] = 'b';
n2.chars[0] = 'b';
n3.chars[0] = 'a';
n3.chars[1] = 'b';
n3.chars[2] = 'c';
n3.chars[3] = 'd';
n3.chars[4] = 'e';
n1.next = n2;
n2.next = n3;
n1.len = 2;
n2.len = 1;
n3.len = 5;
}
}- Follow Up
删除一个数怎么处理,需要注意的地方也就是如果node空了就删掉吧. 那就需要记录前一个node了,这样比较好删掉当前node.
//类似insert,先考虑清楚delete的情况
//1.普通的去掉一个node里面的点.2.去掉node之后,这个点空了,那就把点删掉.
//也要考虑每个node里面长度的变化.
public void delete(int index){
if (index < 0 || index >= totalLen) {
return;
}
Node prev = new Node();
prev.next = head;
Node cur = head;
while(cur != null && index >= 0){
if (index >= cur.len) {
index -= cur.len;
}
else {
if (cur.len == 1) {
prev.next = cur.next;
}
else {
for (int i = index; i < cur.len-1; i++) {
cur.chars[i] = cur.chars[i+1];
}
cur.len -= 1;
}
}
prev = prev.next;
cur = cur.next;
}
totalLen -= 1;
}64.22 Two Sigma OA
Problem Statement
You are given a library with n words (w[0], w[1], …,w[n-1]). You choose a word from it, and in each step, remove one letter from this word only if doing so yields another word in the library. What is the longest possible chain of these removal steps?
Constraints:
1 <= n <= 50000
1 <= the length of each string in w <= 50
Each string is composed of lowercase ascii letters only.
The function should take in an array of strings w as its argument and should return a single integer representing the length of the longest chain of character removals possible.
Example input/output.
a
b
ba
bca
bda
bdca
Calling the function on the input above should output 4. The longest possible chain is “bdca” -> “bca” -> “ba” -> “a”.
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
#include <algorithm>
using namespace std;
int check_chain(const string& s, unordered_map<string,int>& word_map){
int longest=1;
string short_string;
int s_size=s.size();
for(size_t i=0;i<s_size;++i){
short_string=s;
short_string.erase(short_string.begin()+i);
if(word_map.find(short_string)!=word_map.end()){
longest=max(longest, word_map[short_string]+1);
}
}
return longest;
}
int lc_dp(vector<string>& words){
if(words.empty())
return 0;
int n=words.size();
vector<pair<int,string>> s_sorted;
for(string& s:words){
sort(s.begin(),s.end());
s_sorted.push_back({s.size(),s});
}
sort(s_sorted.begin(),s_sorted.end());
unordered_map<string,int> word_map;
word_map.insert({s_sorted[0].second,1});
vector<int> chain_len(n,1);
int longest=1;
for(size_t i=0;i<n;++i){
string s=s_sorted[i].second;
int cl=check_chain(s,word_map);
chain_len[i]=cl;
longest=max(longest, cl);
word_map.insert({s,cl});
}
return longest;
}
int main(){. From 1point 3acres bbs
// vector<string> words{"b","ba","bca","bdca","ebdca"};
// vector<string> w2{"b","ba","bca","bdca","ebdca","b"};
vector<string> w3{"4","9","a","b","bca","ba","bde","bda","bdcae","bdca","abcde"};
// cout<<lc_dp(words)<<endl;
// cout<<lc_dp(w2)<<endl;
cout<<lc_dp(w3)<<endl;
return 0;
}