Chapter 55 Linkedin 2017 Interview Questions Part 2
55.1 151. Reverse Words in a String
https://leetcode.com/problems/reverse-words-in-a-string/
struct Solution {
void reverseWords(string &s) {// Inplace Method
// 1. clean string with two pointers
int k = 0, c = 0, L = s.size();
for (int i = 0; i<L; ++i) {
if (isspace(s[i])){
if (++c >= 2) continue;
}else c = 0;
s[k++] = s[i];
}
s = s.substr(0, k);
// 2. reverse twice
auto reverse_ = [](string &s, int i, int j){ while (i<j) swap(s[i++], s[j--]); };
reverse_(s, 0, s.size() - 1);
int prev = -1, i = 0;
for (; i<s.size()+1; ++i) {
if (isspace(s[i]) || i==s.size()) {
if (prev >= 0) {
reverse_(s, prev, i - 1);
prev = -1;
}
} else {
if (prev == -1) prev = i;
}
}
// strip string
while (s.back() == ' ') s.pop_back();
while (s.front() == ' ') s.erase(s.begin());
}
};- Reverse Words in a String II
https://leetcode.com/problems/reverse-words-in-a-string-ii/
void reverseWords(string &s) {
reverse(s.begin(), s.end());
for (string::iterator i = s.begin(), j = i; j<s.end() + 1; ++j) {
if (j == s.end() || isspace(*j)) {
reverse(i, j);
i = j + 1;
}
}
}- Reverse String
https://leetcode.com/problems/reverse-string
- Reverse String II
https://leetcode.com/problems/reverse-string-ii
- Reverse Vowels of a String
https://leetcode.com/problems/reverse-vowels-of-a-string/
55.2 Top 500 exceptions in 1 hour
http://www.1point3acres.com/bbs/thread-208020-1-1.html
Monitor system的这一轮我面的应该不具备代表性,因为shadow小哥问的太深了,我的解法: 四部分:1. 每个unit收集信息的,然后集中发送到一个collector 2. 处理信息的collector 3. data base 4. 从database读取信息的display system.讨论主要围绕database那个部分展开.load balancing,partition,replication.然后shadow小哥问的深了就涉及到linkedin他家自己系统里的“Router” , “Helix” 和“Zookeeper”.我面试前看了下他家的技术博客,你也可以看一下,挺有帮助的.data.linkedin.com
design monitor system partition 是说horizontal sharding 吗? 感觉是为了存exception 量太大而存在 replication 是为了太多的query 而需要的吗? easy use 能给个hint 吗?
https://github.com/linkedin/kafka-monitor
https://engineering.linkedin.com/blog/2016/05/open-sourcing-kafka-monitor
https://www.confluent.io/blog/stream-data-platform-1/
https://www.careercup.com/question?id=5641031379845120
http://www.jiuzhang.com/qa/12/
http://www.jiuzhang.com/qa/109/
这其实是个异常监控问题

Spark Streaming + Elasticsearch构建App异常监控平台
基于Lua+Kafka+Heka的Nginx Log实时监控系统
logstash联合python kafka进行异常数据监控
Flume+Kafka收集Docker容器内分布式日志应用实践


http://www.1point3acres.com/bbs/thread-229040-1-1.html
55.3 MaxStack
先回顾下leetcode上面那道类似的简单题.
https://leetcode.com/problems/min-stack
class MinStack {
stack<pair<int, int>> stk;
public:
void push(int x) {
if (stk.empty()) {
stk.push({ x, x });
} else {
auto p = stk.top();
if (p.second>x) stk.push({ x,x }); else stk.push({ x,p.second });
}
}
void pop() { stk.pop(); }
int top() { return stk.top().first; }
int getMin() { return stk.top().second; }
};55.4 270. Closest Binary Search Tree Value
5 rounds
1. Given a BST, find the closest k node in the tree. closest means node value.
2. Given number array and k, see if array could be divided to k buckets which all have same sum. Double sqrt(x).
3. Manager round..talking about experiences
4. Design Hangman
5. Tech talk
http://www.1point3acres.com/bbs/thread-229305-1-1.html
tree-traversal.html#closest-binary-search-tree-value-ii
55.5 Weighted Random
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=249822
第一轮是Manager面,我简历最上面的几个project没问,却问我写在最底下才一两行的小项目.我细节早就忘了.最后面试官就和我说不懂的东西不要写在简历上
第二轮两道算法.
1. 给一个数组,找到其中三个数可以组成三角形.一开始我用了O(n^2)的算法,后来想到因为只要返回一组结果,所以其实只要数组排好序后检查连续的三个数就可以了.
2. 设计一个可以O(1)添加key-value对、用key删除、用随机生成的index删除的数据结构,其实就是LC432
第三轮两道算法.
1. 按权重返回随机数.比如{4: 3, 2: 2, 1: 1},就是指4的权为3,2的权为2,1的权为1,那么返回4的概率是1/2.
2. 打印经过城市停车站的所有路线.比如城市0有一个车站X,城市1有A, B两个停车站,2有C, D, E,3有Y.那么从X到Y的所有路线有:
XY 经过1和2时不停车; XAY, XBY 在1停次车; XCY, XDY, XEY 在2停次车; XACY, XADY, XAEY, XBCY, XBDY, XBEY 在1, 2都停次车
我一开始用在一个城市停的结果加上在两个城市停的结果做,面试官就问我这是一个排列还是组合.我没明白他的意思,直到他点明其实这是个排列,就是在每个城市选择每个停车站各一次+不停.
午餐轮的面试官是位美国人,聊了很多东西,比如生活和工作的平衡啦,被微软收购后对公司有什么影响之类的.
第五轮系统设计,输出过去5分钟的, 1个小时的,24个小时的metrics.我的主要思路是按级存储,每分钟的metrics aggregate成5分钟的,然后12个5分钟的metrics aggregate成1小时的.
第六轮我本来以为是系统设计,结果是让我写Delay Scheduler.设计是用min heap存所有任务开始的时间,然后在添加任务或者到下一个任务开始的时候唤醒dispatch线程,根据堆顶任务的时间是否是当前时间决定是否执行任务.我平时写多线程的程序时都是照抄stack overflow的,结果面试的时候就写的磕磕碰碰的了,被面试官指出一大堆错.看来以后要就算是抄代码也要自己读懂了再抄.
第七轮来了两位一看就是senior level的工程师,但是似乎没有准备好要问什么问题.于是一开始先从设计一个可以查询数据的系统开始.我就提出直接用LAMP.然后就问如果增加了Query的QPS怎么办,增加了input的数据量怎么办,我就提到了用sharding啦,Load Balancer啦,Kafka啦之类的,然后分析trade off和计算了下需要的机器数量.
感觉linkedin的面试难度不算大,但是考察的方面特别多,不是靠刷几个月的题就行的.我平时学东西得过且过,不是很深入,以后是要好好改改了.
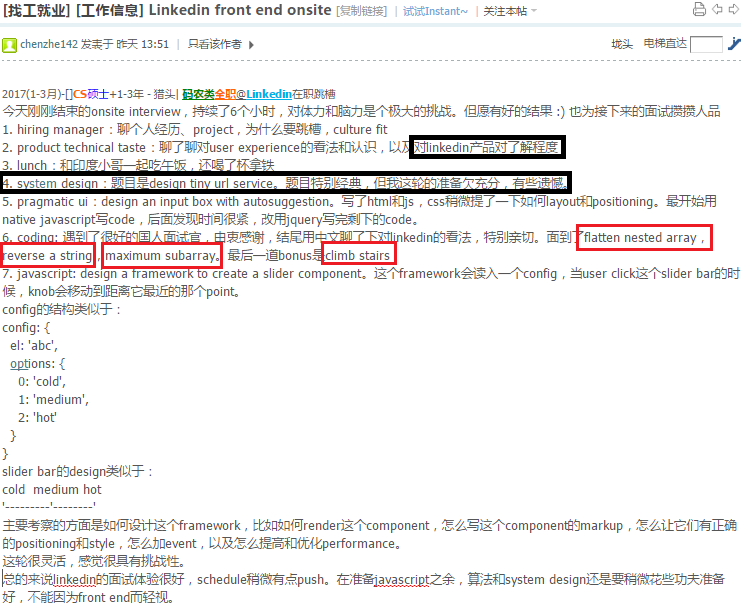
55.6 Coin Change
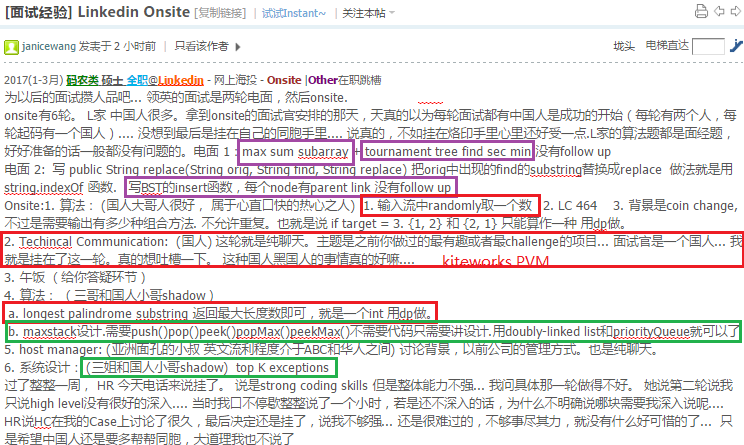
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=266342
https://www.hackerrank.com/challenges/ctci-coin-change?h_r=internal-search
55.7 RTree/Quad Tree/Kd Tree
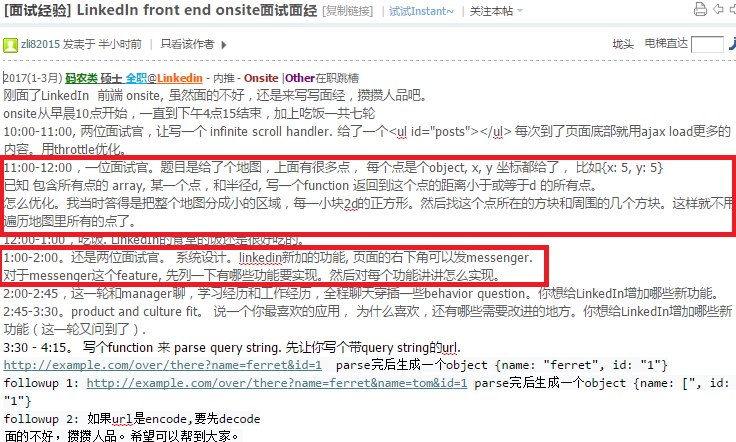
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=270116
11:00-12:00,一位面试官.题目是给了个地图,上面有很多点, 每个点是个object, x, y 坐标都给了, 比如{x: 5, y: 5} 已知 包含所有点的 array, 某一个点,和半径d, 写一个function 返回到这个点的距离小于或等于d 的所有点. 怎么优化.我当时答得是把整个地图分成小的区域,每一小块2d的正方形.然后找这个点所在的方块和周围的几个方块.这样就不用遍历地图里所有的点了.
55.8 design侦测恶意的封包
2017(1-3月) 码农类 硕士 全职@Linkedin - 内推 - Onsite |Other在职跳槽 Linkedin onsite:1. host manager2. 面经add/remove/removeRandom() ,interval题,followup call frequency变化后的结构3. lunch4. max points用double/string来当slope,max k values in a stream,followup滤掉重复的数5. technical communication6. design侦测恶意的封包,一直followup各种骇客的behavoir来破解系统