Chapter 32 Concurrency
参考书籍: Cpp_Concurrency_In_Action.pdf
conditional variable:
std::thread:
32.1 Concurrent Hashmap
http://www.mitbbs.com/article_t1/JobHunting/33281573_0_1.html
According to the methods used to deal with collision, Hashtable设计的两大方案:
32.1.1 Chaining
In Java:
- ConcurrentHashMap
The ConcurrentHashMap is very similar to the java.util.HashTable class, except that ConcurrentHashMap offers better concurrency than HashTable does. ConcurrentHashMap does not lock the Map while you are reading from it. Additionally, ConcurrentHashMap does not lock the entire Map when writing to it. It only locks the part of the Map that is being written to, internally.
http://www.cnblogs.com/huaizuo/p/5413069.html
1.6是基于volatile做的,读不加锁,写保持可见性
1.7, 1.8是基于cas做的,感觉1.6的技巧性更强
http://www.cnblogs.com/mickole/articles/3757278.html
http://www.cnblogs.com/huaizuo/p/5413069.html
ABA of CAS:
http://ifeve.com/atomic-operation/

http://coolshell.cn/articles/8239.html
源码还是能看懂的,看下1.6的是没问题的,1.7 1.8有可能有优化就不好看了
$find . -name ConcurrentHashMap.java |xargs wc -l
1318 ./6/jdk/src/share/classes/java/util/concurrent/ConcurrentHashMap.java
1522 ./7/openjdk/jdk/src/share/classes/java/util/concurrent/ConcurrentHashMap.java
6312 ./8/openjdk/jdk/src/share/classes/java/util/concurrent/ConcurrentHashMap.java
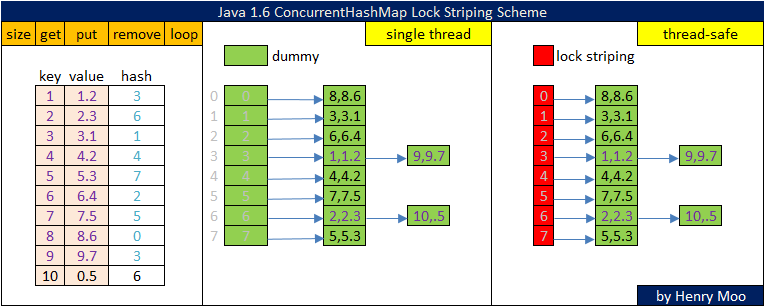
9152 total如果没记错的话,是用到了一种叫 锁分段 技术,具体你可以查一下,相对于hashtable ,concurrenthahmap加了16把锁,也就是说当你对第一个值操作时,只会锁住前两个值,而其他值不受影响.从而由原先竞争1把锁,变成竞争16把锁,所以性能会很高!
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁. ConcurrentHashMap多段加锁解锁要保持顺序的原因是什么?
因为会死锁,如果乱序加锁解锁,两个线程一个加锁,一个解锁调用,极有可能死锁
锁分离技术(Lock Striping): https://www.quora.com/What-is-lock-striping-in-concurrent-programming
Stripe locks:

Partitioning or striping data covered by one lock into parts covered by finer grained locks.
For example you could replace a hash table lock with one on each bucket, for each 1/nth of buckets selected by hash index mod n, etc.
You could replace a red-black tree where the whole thing effectively becomes locked during rebalancing with a skiplist.
http://netjs.blogspot.com/2016/05/lock-striping-in-java-concurrency.html
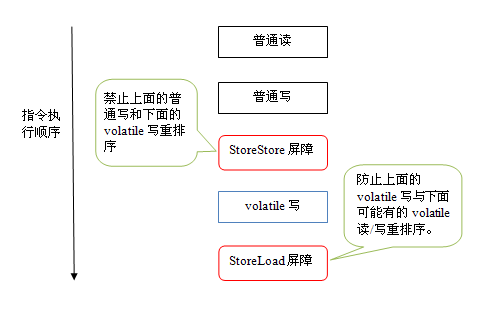
volatile are totally different in C++, C#, Java: https://www.zhihu.com/question/31490495
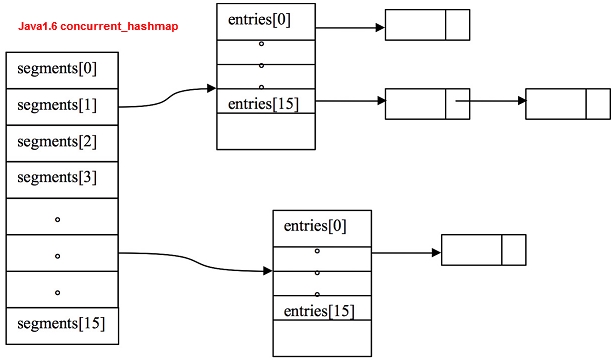
基于Java 6 的分析,非常好:
http://ifeve.com/java-concurrent-hashmap-1/
http://ifeve.com/java-concurrent-hashmap-2/
/**
* ConcurrentHashMap list entry. Note that this is never exported
* out as a user-visible Map.Entry.
*/
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}get() without lock: 其实在整个get函数中还是使用了锁的,不过这段有锁的代码在99.99%的情况下不会执行.
/**
* Reads value field of an entry under lock. Called if value
* field ever appears to be null. This is possible only if a
* compiler happens to reorder a HashEntry initialization with
* its table assignment, which is legal under memory model
* but is not known to ever occur.
*/
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
/* Specialized implementations of map methods */
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}关键点: 1. volatile 2. final
https://www.zhihu.com/topic/20033943/hot
https://www.zhihu.com/question/23235301
https://www.zhihu.com/question/27469719 (**)
concurrentHashMap源码中的readValueUnderLock(e)存在的意义?
https://segmentfault.com/q/1010000006669618
http://stackoverflow.com/questions/41517491/why-readvalueunderlocke-exist-in-concurrenthashmap-s-get-method
http://seanzhou.iteye.com/blog/2031692
get方法(请注意,这里分析的方法都是针对桶的,因为ConcurrentHashMap的最大改进就是将粒度细化到了桶上),首先判断了当前桶的数据个数是否为0,为0自然不可能get到什么,只有返回null,这样做避免了不必要的搜索,也用最小的代价避免出错.然后得到头节点(方法将在下面涉及)之后就是根据hash和key逐个判断是否是指定的值,如果是并且值非空就说明找到了,直接返回;程序非常简单,但有一个令人困惑的地方,这句return readValueUnderLock(e)到底是用来干什么的呢?研究它的代码,在锁定之后返回一个值.但这里已经有一句V v = e.value得到了节点的值,这句return readValueUnderLock(e)是否多此一举?事实上,这里完全是为了并发考虑的,这里当v为空时,可能是一个线程正在改变节点,而之前的get操作都未进行锁定,根据bernstein条件,读后写或写后读都会引起数据的不一致,所以这里要对这个e重新上锁再读一遍,以保证得到的是正确值,这里不得不佩服Doug Lee思维的严密性.整个get操作只有很少的情况会锁定,相对于之前的Hashtable,并发是不可避免的啊!
http://seanzhou.iteye.com/blog/2031692
http://tutorials.jenkov.com/java-concurrency/java-memory-model.html
http://valleylord.github.io/post/201606-memory-model/
注意segment定义:
struct seg {
shared_mutex mu;
hashentry * next;
};
struct hashentry {
int k;
double v;
hashentry* next=0;
int ha;
hashentry():k(0),v(0),ha(0) {}
hashentry(int k_, double v_, int ha_=0):k(k_),v(v_),ha(ha_) {}
};shared_mutex就是一个读写锁.
防止rehash的方法: 1. chaining 2. create new sub-hashtable
32.1.2 Probing + Rehashing or Consistent Hashing?
- Range Partitioning
代表: Redis (https://redis.io/topics/partitioning)
- Hash Partitioning
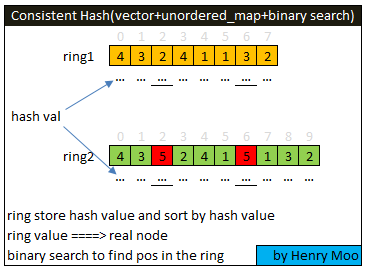
Refer to: - Consistent Hash - http://tutorials.jenkov.com/p2p/peer-routing-table.html
In C++:
Facebook: AtomicHashmap
Video: https://www.facebook.com/Engineering/videos/10151041852263109/
PDF: Massively_Parallel_Datastructures.pdf
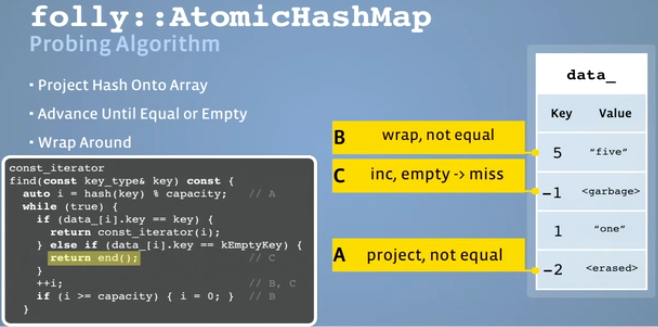
get()/find() 也是lock-free的,甚至没有memory barrier. 对于get的concern主要是怕get的时候write,会得到corrupted data.所以folly在写的时候想办法阻止data corrupted,或者说让data consistent,这样get就不用加锁了.
find:
Insert:
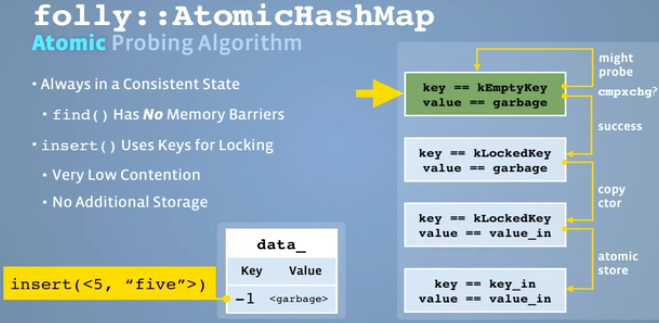
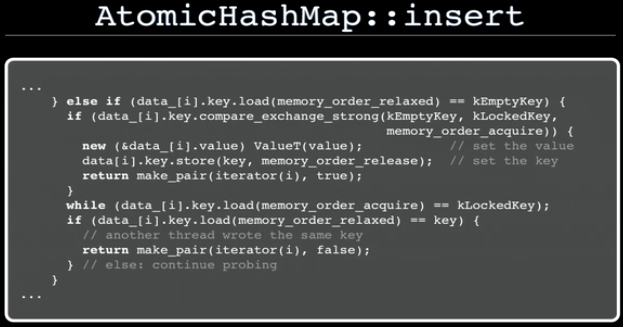
https://github.com/facebook/folly/blob/master/folly/AtomicHashMap-inl.h#L102
Grow(Consistent Hashing, no rehashing):
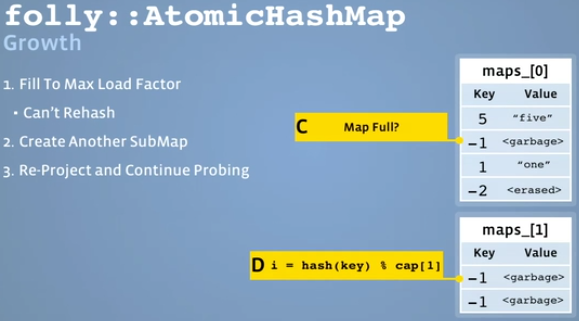
Erase:
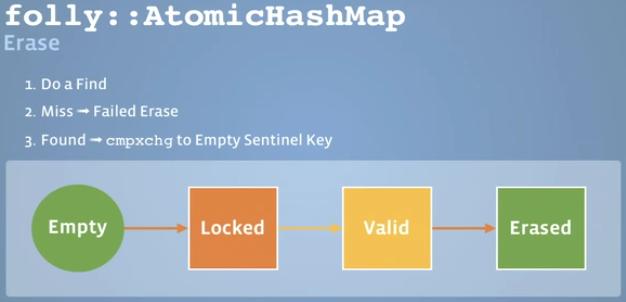
Remaing Issues:
- Tracking Size
背景是不经常call size()这个函数,但是有24个甚至更多core, 很多的线程在同时写.
解决方法1. 是用int array, 每个线程写各自的int counter,最后加起来; 2.是用thread local int.
Some cool takeaways:
Open addressing style
Growing hashmap: create another submap instead of rehash
Compare and swap for insert
ThreadCachedInt
Thread Local Storage
Microsharding when atomic inc is a bottleneck
Modulus is too slow for calculating the hash: so take mod on next power of two and use bit ops
What's the optimal size? Branch misprediction becomes a factor too.Limitation Example: https://issues.apache.org/jira/browse/HBASE-18214
Intel: concurrent_hash_map
https://github.com/01org/tbb/blob/tbb_2017/include/tbb/concurrent_hash_map.h
RCU是另一个能替换读写锁的方法: http://codemacro.com/2015/04/19/rw_thread_gc/
32.2 Sinlge Blocking Queue
One Producer One Consumer - Look Free required!
https://github.com/facebook/folly/blob/master/folly/ProducerConsumerQueue.h
32.3 Bounded Blocking Queue
Multiple Producer Multiple Consumer
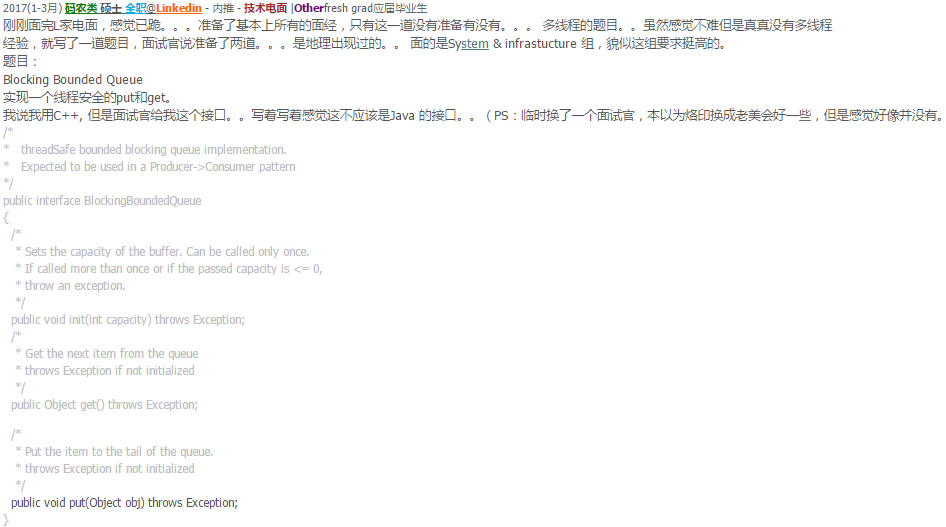
这题让实现一个BBQ. There could be multiple producer and consumer threads. Producers fill up the queue. If the queue is full, producers should wait; On the other hand, consumers take elements from the queue. If the queue is empty, consumers should wait.
template <typename T>
struct BBQ {
int32_t MAXCOUNT;
queue<T> Q;
mutex mu;
condition_variable cv;
BBQ(const BBQ&) = delete; // noncopyable
BBQ &operator=(const BBQ&) = delete; // nonassignable
BBQ():MAXCOUNT(-1) {}
void init(int32_t c) {
if (c <= 0) throw exception("maxcount must be greater than 0");
MAXCOUNT = c;
}
template <typename T>
void put(const T& item) { // producer
if (MAXCOUNT == -1) throw exception("uninitialized MAXCOUNT");
unique_lock<mutex> lk(mu);
while (Q.size() == MAXCOUNT) {//spurious wake
cv.wait(lk);
}
Q.push(item);
//lk.unlock(); // wrong!!!
if (Q.size() == 1) // BBQ里面有一个东西就表示可取了,所以用1
cv.notify_one();
}
template <typename T>
T get() { // consumer
if (MAXCOUNT == -1) throw exception("uninitialized MAXCOUNT");
unique_lock<mutex> lk(mu);
while (Q.size() == 0) {
cv.wait(lk);
}
T r = Q.front();
Q.pop();
//lk.unlock(); // wrong!!!
//每次取一个所以减一,如果每次取2个应该减2
if (Q.size() == MAXCOUNT - 1)
cv.notify_one();
return r;
}
};-
注意
cv.wait(lk)的时候,lk会被解锁,所以其他线程就可以干活了. -
在c++11里面,等的是lock,不是mutex.而且这个lock必须是unique_lock.这是在函数的signature里面定义的.
Exception specifications are a C++ language feature that is deprecated in C++11. They were designed to provide summary information about what exceptions can be thrown out of a function, but in practice they were found to be problematic. The one exception specification that did prove to be somewhat useful was the throw() specification. - MSDN
C++11的condition_variable其实支持spurious wake check的功能.上面的put函数里面的while loop其实可以用一行代替:
后面的predicate是跳出循环的条件.
其他思考:
1. 如果Queue不是bounded的话(就是BQ),put函数可以一直不停的加数据,不会睡,所以put函数的cv.wait()和get函数的cv.notify_one()要去掉.
2. STL的pop很危险,如果empty还pop的话,就会有undefined behavior(UB).
3. 上面的是多线程读写BBQ,get函数会block,所以不会出现STL里面的pop的UB情况.
下面这个视频Deadlock and Condition Variables讲了如何实现一个producer-consumer的Queue.
还可以参考Folly的MPMCQueue:
https://github.com/facebook/folly/blob/master/folly/MPMCQueue.h
MPMCQueue
is a high-performance bounded concurrent queue that supports multiple producers, multiple consumers, and optional blocking. The queue has a fixed capacity, for which all memory will be allocated up front. The bulk of the work of enqueuing and dequeuing can be performed in parallel.
32.4 Design a DelayQueue
先看一些现有的解决方案:
32.4.1 Bloomberg BDE’s timequeue.
https://bloomberg.github.io/bde/group__bdlcc__timequeue.html#_details
里面的server定时踢掉过期session的例子很经典.
https://bloomberg.github.io/bde/namespacebdlcc.html 这里面还有一个线程安全的skiplist的实现,而且带有一个simplescheduler的例子.
The “R” methods of bdlcc::SkipList make it ideal for use in a
scheduler, in which events are likely to be scheduled after existing events. In such an implementation, events are stored in the list with their scheduled execution times as KEY objects: Searching near the end of the list for the right location for new events, and removing events from the front of the list for execution, are very efficient operations.
用skiplist又提供了除priority_queue之外的一种新思路.
Provide a thread-safe recurring and one-time event scheduler.
https://bloomberg.github.io/bde/group__bdlmt__eventscheduler.html
Provide a thread-safe recurring and non-recurring event scheduler.
https://bloomberg.github.io/bde/group__bdlmt__timereventscheduler.html
32.4.2 Facebook Folly
感觉这就是一个timer queue,在folly里面发现了一个TimeoutQueue.
https://github.com/facebook/folly/blob/master/folly/TimeoutQueue.h
https://github.com/facebook/folly/blob/master/folly/TimeoutQueue.cpp
https://github.com/facebook/folly/blob/master/folly/test/TimeoutQueueTest.cpp
看了folly的源码发现std::move居然在C++11里面有两个定义,一个在utility里面,一个在algorithm里面.
里面的底层数据结构使用的是boost::multi_index_container.
还有里面并没有用cv.wait().所以好像不是我要找的东西.
32.4.3 JDK DelayQueue
这个高级一点使用了并发设计模式Leader/Followers Pattern: http://www.cs.wustl.edu/~schmidt/PDF/lf.pdf
但看到这段java代码的时候,感觉c++的destructor真好啊:
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e);
if (q.peek() == e) {
leader = null;
available.signal();
}
return true;
} finally {
lock.unlock();
}
}感觉这个就是我要的东西.
http://www.importnew.com/7276.html ??
2015(10-12月) 码农类 硕士 全职 Linkedin - Other - Onsite |Failfresh grad应届毕业生 第一次发面筋 上周二面的,今天拿到结果.整体感觉很棒,结果不怎么样… 1. 设计数据结构,能够add(), remove(), randomremove() in O(1)复杂度.去之前看到过这题,但是自己没写过,面的时候卡了半天,最后还是有一个bug没空改了,估计就坑爹在这里.
2. 设计Delay Scheduler,能够把task schedule在特定的时间执行.3. 设计一个Message Broker 4. 判断两棵树相同,mergeKSortedLists, max points on a line.

http://www.1point3acres.com/bbs/thread-161803-1-1.html
3这一步可以优化一下,不用polling. 你需要一个单独的thread来维护那个队列,调用task. 通过wait, notify来唤醒thread.每次schedule一个新的任务后,call notify唤醒scheduling thread.被唤醒后,查看任务是否到时,如果没有任何任务到时,这wait相应的时间. 具体代码推荐参考Java timer class source code.不复杂.
Q: 大牛,我java concurrency不熟,想请教下这个地方每次schedule新的任务才去wake notify那个timer thread的话,会不会错过队列顶的任务的delay时间?
A:不会,thread 在call wait 函数的时候可以传waiting time parameter,就设成栈顶那个任务的等待时间.这段时间内如果没有新的任务加进来,thread will wake up automatically after the waiting time expired
我觉得一个比较好的办法如下:
1. 每来一个task,define start_time = cur_time + delay
2. 设置一个Heap of task, 以task.start_time排序,最小的放在top
3. 把当前task加入Heap,set timer = (Heap.top.start_time - cur_time)
4. 当timer到时间激发时,run task = Heap.top; Heap.remove_top; set timer = (Heap.top.start_time - cur_time)
http://lfl2011.iteye.com/blog/2277290
Java’s DelayQueue是一个支持延时获取元素的unbounded blocking queue.队列使用PriorityQueue来实现.队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素.只有在延迟期满时才能从队列中提取元素.我们可以将DelayQueue运用在以下应用场景:
缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了.
定时任务调度:使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的.
从这个博客的例子来看DelayQueue确实很好用.但是他采用的是polling的方法,每0.3秒试着从queue里面拖些到期的东西出来. 感觉也不是很好.
32.4.4 Final Solution
 下面的解法就是面试解法.
下面的解法就是面试解法.
struct event {
int id;
time_t due;
void remind() {
cout << "\t\t\t | Trigger event " << id << " at "
<< due << endl;
};
};
struct comp {
bool operator()(const event& t1, const event& t2) {
return t1.due > t2.due;
};
};
// minheap
priority_queue<event, vector<event>, comp> DelayQueue;
mutex mu;
condition_variable cv;
void consumer() {
unique_lock<mutex> ul(mu);
while (1) { //两个while循环,两次cv.wait/wait_for
while (DelayQueue.empty()) {cv.wait(ul);}
auto tmp = DelayQueue.top();
auto now = time(NULL);
if (tmp.due <= now) {
tmp.remind();
DelayQueue.pop();
} else {
cv.wait_for(ul, (tmp.due - now) * 1s);
}
}
}
void producer() {
int i = 0;
event t;
while (1) {
{//加这个括号避免starvation!!!!
lock_guard<mutex> ul(mu);
t.id = i++;
t.due = time(NULL) + rand()%10;
DelayQueue.push(t);
cv.notify_one();
cout << "Add event "<<t.id<<"("<<t.due<<")\n";
}// never hold lock when sleeping
this_thread::sleep_for(3s);
}
}
void producer2(const event& tsk) {
lock_guard<mutex> ul(mu);
DelayQueue.push(tsk);
cv.notify_one();
}
void main() {
cout << "producer\t\t |consumer\n";
cout << string(60,'-') << endl;
thread tproducer(producer);
thread tconsumer(consumer);
tproducer.join();
tconsumer.join();
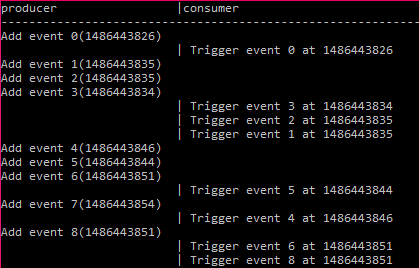
}运行的结果是:
32.5 Inplement A Deadlock
银行转账是一个很好的例子:
struct account {
double deposit=100.0;
mutex mu;
};
void transfermoney(account& from, account& to, double money) {
lock_guard<mutex> lock1(from.mu);
this_thread::sleep_for(5s);
lock_guard<mutex> lock2(to.mu);
from.deposit -= money;
to.deposit += money;
}
void deadlock() {
account jack, simon;
thread t1(transfermoney, ref(jack), ref(simon), 10.5);
thread t2(transfermoney, ref(simon), ref(jack), 1.5);
t1.join(), t2.join();
}解决的方法是利用account的id(假设每个account有一个id),先锁大id,再锁小id.
上面那个一个线程睡5秒应该在99.999%甚至以上的情况下会死锁,但是理论上还不能保证必然死锁.可以用下面的方法保证绝对死锁:
struct account {
double deposit=0;
mutex mu;
bool locked=false;
};
void transfermoney(account& from, account& to, double money) {
lock_guard<mutex> lock1(from.mu);
//这行保证必然死锁!
from.locked = true; while(!to.locked) this_thread::sleep_for(1s);
lock_guard<mutex> lock2(to.mu);
from.deposit -= money;
to.deposit += money;
}
void deadlock() {
account jack, simon;
thread t1(transfermoney, ref(jack), ref(simon), 10.5);
thread t2(transfermoney, ref(simon), ref(jack), 1.5);
t1.join(), t2.join();
}注意如果一个mutex被同一个线程锁两次,第二次锁的时候不一定是死锁.(是undefined behavior)
根据我的测试在vs2015 windows下面会抛出system_error异常, 在linux g++ 5.2.1下面就直接忽略继续执行.
32.6 Ticket Algorithm
The ticket algorithm aims to solve the problem of starvation: when one thread has to wait for ages before it is let acquire the mutex, while another thread (or multiple other threads) might be acquiring it over and over in the mean time.
#include <iostream>
#include <atomic>
#include <thread>
#include <mutex>
#include <sstream>
using namespace std;
const int n = 10;
atomic_int _number;
atomic_int _next;
atomic_int _turn[n];
int numThreads;
mutex coutMutex;
ostringstream data;
void func() {
int i = numThreads++; //Intentional post-increment
coutMutex.lock();
cout << "Thread " << i << " reporting in." << endl;
coutMutex.unlock();
this_thread::sleep_for(chrono::milliseconds(rand() % 500 + 500));
while (true){
//Take a ticket
_turn[i] = _number.fetch_add(1);
//Using a mutex for output so that threads don't uppercut
//each other on the console.
coutMutex.lock();
cout << "t" << i << "\tturn: " << _turn[i] << endl;
coutMutex.unlock();
//Slow down the program so that we can read the console.
this_thread::sleep_for(chrono::milliseconds(rand() % 500 + 500));
while (_turn[i] != _next)
{
continue;
}
coutMutex.lock();
cout << "t" << i << "\t+CS" << endl;
coutMutex.unlock();
//critical section
data << " data_t" << i;
//exit protocol
_next += 1;
coutMutex.lock();
cout << data.str() << endl;
cout << "t" << i << "\tnext = " << _next << endl;
coutMutex.unlock();
}
}
int _tmain(int argc, _TCHAR* argv[])
{
srand(time(NULL));
data = ostringstream();
numThreads = 0;
_number = 1;
_next = 1;
for (int i = 0; i < n; i++)
{
_turn[i] = 0;
}
thread t1 = thread(func);
thread t2 = thread(func);
//thread t3 = thread(func); //Add as many threads as you like
//thread t4 = thread(func);
//thread t5 = thread(func);
t1.join();
t2.join();
//t3.join();
//t4.join();
//t5.join();
return 0;
}32.7 Making Water
这个题目的意思是有很多可以生产氢原子和氧原子的线程,每个线程负责生成一个原子(或者氢原子或者氧原子).现在要用一个氧原子和两个氢原子生成一个水分子.比如用H代表一个生成氢原子的线程,O代表生成氧原子的线程.程序生成原子和分子的顺序必须是先生成两个氢原子和一个氧原子再生产一个水分子,比如: HHOOHHHOH,但是不可以是HHOHHHOOH.
这个题可以看作氢原子线程是BBQ长度为2的producer;氧原子线程是consumer,它去BBQ里面一次取走2个氢原子然后make water. 所以可以套用上面的BBQ的代码.
namespace watermaker{
mutex gm;
atomic<int> hc = 0, oc = 0;
condition_variable cv;
void h() {
unique_lock<mutex> gl(gm);
while (hc == 2) {
cv.wait(gl);
}
hc++;// make hydrogen
cv.notify_one();
}
void o() {
unique_lock<mutex> gl(gm);
while (hc != 2) {
cv.wait(gl);
}
oc++;// make oxygen
hc -= 2, --oc; // make water
cv.notify_one();
}
void run(int n) {
vector<thread*> threads;
for (int i = 0; i < n; ++i) {
threads.push_back(new thread(h));
threads.push_back(new thread(h));
threads.push_back(new thread(o));
}
for_each(threads.begin(), threads.end(), [](thread* t) {
if (t->joinable()) t->join(), delete t; });
}
}其实这里oc都没有必要,因为一个氧原子线程必然产生一个氧原子然后再消耗掉.所以关键是氢原子的数量hc.
Follow up: 如果产生双氧水\(H_2O_2\),最好再开一个线程叫做h2o2作为consumer,原来的氧原子线程就变成了producer. 这样就是一个2个producer,2个BBQ,1个consumer. 代码如下:
32.8 When should one use a spinlock instead of mutex?
https://stackoverflow.com/questions/5869825/when-should-one-use-a-spinlock-instead-of-mutex
The Theory
In theory, when a thread tries to lock a mutex and it does not succeed, because the mutex is already locked, it will go to sleep, immediately allowing another thread to run. It will continue to sleep until being woken up, which will be the case once the mutex is being unlocked by whatever thread was holding the lock before. When a thread tries to lock a spinlock and it does not succeed, it will continuously re-try locking it, until it finally succeeds; thus it will not allow another thread to take its place (however, the operating system will forcefully switch to another thread, once the CPU runtime quantum of the current thread has been exceeded, of course).
The Problem
The problem with mutexes is that putting threads to sleep and waking them up again are both rather expensive operations, they’ll need quite a lot of CPU instructions and thus also take some time. If now the mutex was only locked for a very short amount of time, the time spent in putting a thread to sleep and waking it up again might exceed the time the thread has actually slept by far and it might even exceed the time the thread would have wasted by constantly polling on a spinlock. On the other hand, polling on a spinlock will constantly waste CPU time and if the lock is held for a longer amount of time, this will waste a lot more CPU time and it would have been much better if the thread was sleeping instead.
The Solution
Using spinlocks on a single-core/single-CPU system makes usually no sense, since as long as the spinlock polling is blocking the only available CPU core, no other thread can run and since no other thread can run, the lock won’t be unlocked either. IOW, a spinlock wastes only CPU time on those systems for no real benefit. If the thread was put to sleep instead, another thread could have ran at once, possibly unlocking the lock and then allowing the first thread to continue processing, once it woke up again.
On a multi-core/multi-CPU systems, with plenty of locks that are held for a very short amount of time only, the time wasted for constantly putting threads to sleep and waking them up again might decrease runtime performance noticeably. When using spinlocks instead, threads get the chance to take advantage of their full runtime quantum (always only blocking for a very short time period, but then immediately continue their work), leading to much higher processing throughput.
The Practice
Since very often programmers cannot know in advance if mutexes or spinlocks will be better (e.g. because the number of CPU cores of the target architecture is unknown), nor can operating systems know if a certain piece of code has been optimized for single-core or multi-core environments, most systems don’t strictly distinguish between mutexes and spinlocks. In fact, most modern operating systems have hybrid mutexes and hybrid spinlocks. What does that actually mean?
A hybrid mutex behaves like a spinlock at first on a multi-core system. If a thread cannot lock the mutex, it won’t be put to sleep immediately, since the mutex might get unlocked pretty soon, so instead the mutex will first behave exactly like a spinlock. Only if the lock has still not been obtained after a certain amount of time (or retries or any other measuring factor), the thread is really put to sleep. If the same code runs on a system with only a single core, the mutex will not spinlock, though, as, see above, that would not be beneficial.
A hybrid spinlock behaves like a normal spinlock at first, but to avoid wasting too much CPU time, it may have a back-off strategy. It will usually not put the thread to sleep (since you don’t want that to happen when using a spinlock), but it may decide to stop the thread (either immediately or after a certain amount of time) and allow another thread to run, thus increasing chances that the spinlock is unlocked (a pure thread switch is usually less expensive than one that involves putting a thread to sleep and waking it up again later on, though not by far).
Summary
If in doubt, use mutexes, they are usually the better choice and most modern systems will allow them to spinlock for a very short amount of time, if this seems beneficial. Using spinlocks can sometimes improve performance, but only under certain conditions and the fact that you are in doubt rather tells me, that you are not working on any project currently where a spinlock might be beneficial. You might consider using your own “lock object”, that can either use a spinlock or a mutex internally (e.g. this behavior could be configurable when creating such an object), initially use mutexes everywhere and if you think that using a spinlock somewhere might really help, give it a try and compare the results (e.g. using a profiler), but be sure to test both cases, a single-core and a multi-core system before you jump to conclusions (and possibly different operating systems, if your code will be cross-platform).